Available with limitations in: CE, BE, SE, SE+, CSE Lite (1.73)
Available without limitations in: EE
The module lifecycle stage: General Availability
Web interfaces associated with the module: istio
Compatibility table for supported versions
| Istio version | K8S versions supported by Istio | Status in D8 |
|---|---|---|
| 1.25 | 1.29, 1.30, 1.31, 1.32 | Supported |
| 1.21 | 1.26, 1.27, 1.28, 1.29, 1.30, 1.31 | Deprecated and will be deleted |
What issues does Istio help to resolve?
Istio is a framework for managing network traffic on a centralized basis that implements the Service Mesh approach.
Istio solves the tasks for applications:
- Compatibility table for supported versions
- What issues does Istio help to resolve?
- Mutual TLS
- Authorization
- Request routing
- Managing request balancing between service Endpoints
- Observability
- Architecture of the cluster with Istio enabled
- Application service architecture with Istio enabled
- Activating Istio to work with the application
- Federation and multicluster
- Estimating overhead
Mutual TLS
Mutual TLS is the main method of mutual service authentication. It is based on the fact that all outgoing requests are verified using the server certificate, and all incoming requests are verified using the client certificate. After the verification is complete, the sidecar-proxy can identify the remote node and use these data for authorization or auxiliary purposes.
Each service gets its own identifier of the following format: <TrustDomain>/ns/<Namespace>/sa/<ServiceAccount> where TrustDomain is the cluster domain in our case. You can assign your own ServiceAccount to each service or use the regular “default” one. The service ID can be used for authorization and other purposes. This is the identifier used as a name to validate against in TLS certificates.
You can redefine this settings at the Namespace level.
Authorization
The AuthorizationPolicy resource is responsible for managing authorization. Once this resource is created for the service, the following algorithm is used for determining the fate of the request:
- The request is denied if it falls under the DENY policy.
- The request is allowed if there are no ALLOW policies for the service.
- The request is allowed if it falls under the ALLOW policy.
- In all other cases, the request is denied.
In other words, if you explicitly deny something, then only this restrictive rule will work. On the other hand, if you explicitly allow something, only explicitly authorized requests would be allowed (however, restrictions will have precedence).
You can use the following arguments for defining authorization rules:
- Service IDs and wildcard expressions based on them (
mycluster.local/ns/myns/sa/myappormycluster.local/*) - Namespace
- IP ranges
- HTTP headers
- JWT tokens
Request routing
VirtualService is the main resource for routing control; it allows you to override the destination of an HTTP or TCP request. Routing decisions can be based on the following parameters:
- Host or other headers
- URI
- Method (GET, POST, etc.)
- Pod labels or the namespace of the request source
- dst-IP or dst-port for non-HTTP requests
Managing request balancing between service Endpoints
DestinationRule is the main resource for managing request balancing; it allows you to configure the details of requests leaving the Pods:
- Limits/timeouts for TCP
- Balancing algorithms between Endpoints
- Rules for detecting problems on the Endpoint side to take it out of balancing
- Encryption details
All customizable limits apply to each client Pod individually (on a per Pod basis)! Suppose you limited a service to one TCP connection. In this case, if you have three client Pods, the service will get three incoming connections.
Observability
Tracing
Istio makes it possible to collect application traces and inject trace headers if there are none. In doing so, however, you have to keep in mind the following:
- If a request initiates secondary requests for a service, they must inherit the trace headers by means of the application.
- You will need to install Jaeger to collect and display traces.
Grafana
The standard module bundle includes the following additional dashboards:
- Dashboard for evaluating the throughput and success of requests/responses between applications.
- Dashboard for evaluating control plane performance and load.
Kiali
Kiali is a tool for visualizing your application’s service tree. It allows you to quickly assess the situation in the network connectivity by visualizing the requests and their quantitative characteristics directly on the scheme.
Architecture of the cluster with Istio enabled
The cluster components are divided into two categories:
- Control plane — managing and maintaining services; “control-plane” usually refers to istiod Pods;
- Data plane — mediating and controlling all network communication between microservices, it is composed of a set of sidecar-proxy containers.
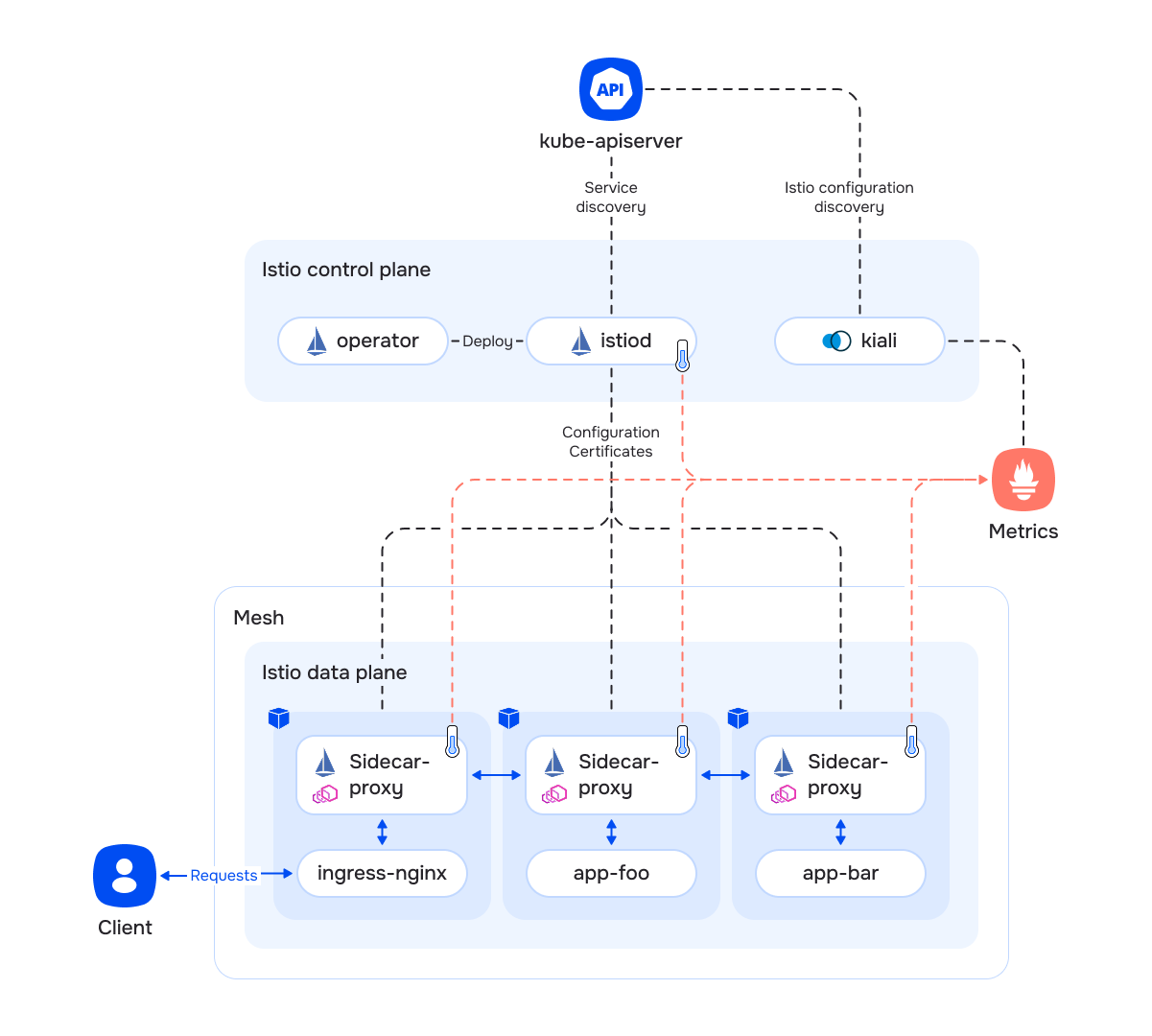
All data plane services are grouped into a mesh with the following features:
- It has a common namespace for generating service ID in the form
<TrustDomain>/ns/<Namespace>/sa/<ServiceAccount>. Each mesh has a TrustDomain ID (in our case, it is the same as the cluster domain), e.g.mycluster.local/ns/myns/sa/myapp. - Services within a single mesh can authenticate each other using trusted root certificates.
Control plane components:
istiod— the main service with the following tasks:- Continuous connection to the Kubernetes API and collecting information about services.
- Processing and validating all Istio-related Custom Resources using the Kubernetes Validating Webhook mechanism.
- Configuring each sidecar proxy individually:
- Generating authorization, routing, balancing rules, etc..
- Distributing information about other application services in the cluster.
- Issuing individual client certificates for implementing Mutual TLS. These certificates are unrelated to the certificates that Kubernetes uses for its own service needs.
- Automatic tuning of manifests that describe application Pods via the Kubernetes Mutating Webhook mechanism:
- Injecting an additional sidecar-proxy service container.
- Injecting an additional init container for configuring the network subsystem (configuring DNAT to intercept application traffic).
- Routing readiness and liveness probes through the sidecar-proxy.
operator— installs all the resources required to operate a specific version of the control plane.kiali— dashboard for monitoring and controlling Istio resources as well as user services managed by Istio that allows you:- Visualize inter-service connections.
- Diagnose problem inter-service connections.
- Diagnose the control plane state.
The Ingress controller must be refined to receive user traffic:
- You need to add sidecar-proxy to the controller Pods. It only handles traffic from the controller to the application services (the
enableIstioSidecarparameter of theIngressNginxControllerresource). - Services not managed by Istio continue to function as before, requests to them are not intercepted by the controller sidecar.
- Requests to services running under Istio are intercepted by the sidecar and processed according to Istio rules (read more about activating Istio to work with the application).
The istiod controller and sidecar-proxy containers export their own metrics that the cluster-wide Prometheus collects.
Application service architecture with Istio enabled
Details
- Each service Pod gets a sidecar container — sidecar-proxy. From the technical standpoint, this container contains two applications:
- Envoy proxies service traffic. It is responsible for implementing all the Istio functionality, including routing, authentication, authorization, etc.
- pilot-agent is a part of Istio. It keeps the Envoy configurations up to date and has a built-in caching DNS server.
- Each Pod has a DNAT configured for incoming and outgoing service requests to the sidecar-proxy. The additional init container is used for that. Thus, the traffic is routed transparently for applications.
- Since incoming service traffic is redirected to the sidecar-proxy, this also applies to the readiness/liveness traffic. The Kubernetes subsystem that does this doesn’t know how to probe containers under Mutual TLS. Thus, all the existing probes are automatically reconfigured to use a dedicated sidecar-proxy port that routes traffic to the application unchanged.
- You have to configure the Ingress controller to receive requests from outside the cluster:
- The controller’s Pods have additional sidecar-proxy containers.
- Unlike application Pods, the Ingress controller’s sidecar-proxy intercepts only outgoing traffic from the controller to the services. The incoming traffic from the users is handled directly by the controller itself;
- Ingress resources require refinement in the form of adding annotations:
nginx.ingress.kubernetes.io/service-upstream: "true"— the Ingress controller will use the service’s ClusterIP as upstream instead of the Pod addresses. In this case, traffic balancing between the Pods is handled by the sidecar-proxy. Use this option only if your service has a ClusterIP.nginx.ingress.kubernetes.io/upstream-vhost: "myservice.myns.svc"— the Ingress controller’s sidecar-proxy makes routing decisions based on the Host header. If this annotation is omitted, the controller will leave a header with the site address (e.g.Host: example.com).
- Resources of the Service type do not require any adaptation and continue to function properly. Just like before, applications have access to service addresses like
servicename,servicename.myns.svc, etc; - DNS requests from within the Pods are transparently redirected to the sidecar-proxy for processing:
- This way, domain names of the services in the neighboring clusters can be disassociated from their addresses.
User request lifecycle
Application with Istio turned off
Application with Istio turned on
Activating Istio to work with the application
The main purpose of the activation is to add a sidecar container to the application Pods so that Istio can manage the traffic.
The sidecar-injector is a recommended way to add sidecars. Istio can inject sidecar containers into user Pods using the Admission Webhook mechanism. You can configure it using labels and annotations:
- A label attached to a namespace allows the sidecar-injector to identify a group of Pods to inject sidecar containers into:
istio-injection=enabled— use the global version of Istio (spec.settings.globalVersioninModuleConfig);istio.io/rev=v1x16— use the specific Istio version for a given namespace.
- The
sidecar.istio.io/inject("true"or"false") Pod annotation lets you redefine thesidecarInjectorPolicypolicy locally. These annotations work only in namespaces to which the above labels are attached.
It is also possible to add the sidecar to an individual pod in namespace without the istio-injection=enabled or istio.io/rev=vXxYZ labels by setting the sidecar.istio.io/inject=true Pod label.
Note! Istio-proxy, running as a sidecar container, consumes resources and adds overhead:
- Each request is DNAT’ed to Envoy that processes it and creates another one. The same thing happens on the receiving side.
- Each Envoy stores information about all the services in the cluster, thereby consuming memory. The bigger the cluster, the more memory Envoy consumes. You can use the Sidecar CustomResource to solve this problem.
The EnvoyFilter interface can be controlled by Lua plugins, but it is an internal control mechanism for implementing the Istio functionality. It must not be used in a user configuration, as doing so would compromise the integrity of the system.
It is also important to get the Ingress controller and the application’s Ingress resources ready:
- Enable
enableIstioSidecarof theIngressNginxControllerresource. - Add annotations to the application’s Ingress resources:
nginx.ingress.kubernetes.io/service-upstream: "true"— the Ingress controller will use the service’s ClusterIP as upstream instead of the Pod addresses. In this case, traffic balancing between the Pods is now handled by the sidecar-proxy. Use this option only if your service has a ClusterIP.nginx.ingress.kubernetes.io/upstream-vhost: "myservice.myns.svc"— the Ingress controller’s sidecar-proxy makes routing decisions based on the Host header. If this annotation is omitted, the controller will leave a header with the site address (e.g.Host: example.com).
Federation and multicluster
Available in Enterprise Edition only.
Deckhouse supports two schemes of inter-cluster interaction:
Below are their fundamental differences:
- The federation aggregates multiple sovereign (independent) clusters:
- Each cluster has its own namespace (for Namespace, Service, etc.);
- Access to individual services between clusters is clearly defined.
- The multicluster aggregates co-dependent clusters:
- Cluster namespaces are shared — each service is available to neighboring clusters as if it were running in a local cluster (unless authorization rules prohibit that).
Federation
Requirements for clusters
- Each cluster must have a unique domain in the
clusterDomainparameter of the resource ClusterConfiguration. The default value iscluster.local. -
Pod and Service subnets in the
podSubnetCIDRandserviceSubnetCIDRparameters of the resource ClusterConfiguration can be the same. -
Each cluster must have a unique domain in the
clusterDomainparameter of the resource ClusterConfiguration. Please note that none of the clusters should use the domaincluster.local, which is the default setting.cluster.localis an unmodified alias for the local cluster domain. When specifyingcluster.localas a principals in the AuthorizationPolicy, it will always refer to the local cluster, even if there is another cluster in the mesh withclusterDomainexplicitly defined ascluster.local. source -
Pod and Service subnets in the
podSubnetCIDRandserviceSubnetCIDRparameters of the resource ClusterConfiguration must be unique for each federation member.- When analyzing HTTP and HTTPS traffic (in istio terminology), you can identify them and decide on further routing or blocking based on their headers.
- At the same time, when analyzing TCP traffic (in istio terminology), it is possible to identify them and decide on further routing or blocking based only on their destination IP address or port number.
Istio operates in the multi-network mode — pods from different clusters can only communicate with each other through the Istio ingress gateway. Direct communication between pods of different clusters is not supported.
General principles of federation
- Federation requires mutual trust between clusters. Thereby, to use federation, you have to make sure that both clusters (say, A and B) trust each other. This is achieved by a mutual exchange of root certificates.
- You also need to share information about government services to use the federation. You can do that using ServiceEntry. A service entry defines the public ingress-gateway address of the B cluster so that services of the A cluster can communicate with the bar service in the B cluster.
Enabling the federation
Enabling federation (via the istio.federation.enabled = true module parameter) results in the following activities:
- The
ingressgatewayservice is added to the cluster. Its task is to proxy mTLS traffic coming from outside of the cluster to application services. - A service gets added to the cluster that exports the following cluster metadata to the outside:
- Istio root certificate (accessible without authentication).
- List of public services in the cluster (available only for authenticated requests from neighboring clusters).
- List of public addresses of the
ingressgatewayservice (available only for authenticated requests from neighboring clusters).
Managing the federation
To establish a federation, you must:
- Create a set of
IstioFederationresources in each cluster that describe all the other clusters.- After successful auto-negotiation between clusters, the status of
IstioFederationresource will be filled with neighbour’s public and private metadata (status.metadataCache.publicandstatus.metadataCache.private).
- After successful auto-negotiation between clusters, the status of
- Add the
federation.istio.deckhouse.io/public-service: ""label to each resource(service) that is considered public within the federation.- In the other federation clusters, a corresponding
ServiceEntrywill be created for eachservice, leading to theingressgatewayof the original cluster.
- In the other federation clusters, a corresponding
In the .spec.ports section of services, each port must have the name field filled.
Multicluster
Requirements for clusters
- Cluster domains in the
clusterDomainparameter of the resource ClusterConfiguration must be the same for all multicluster members. The default value iscluster.local. -
Pod and Service subnets in the
podSubnetCIDRandserviceSubnetCIDRparameters of the resource ClusterConfiguration must be unique for each multicluster member.- When analyzing HTTP and HTTPS traffic (in istio terminology), you can identify them and decide on further routing or blocking based on their headers.
- At the same time, when analyzing TCP traffic (in istio terminology), it is possible to identify them and decide on further routing or blocking based only on their destination IP address or port number.
If the IP addresses of services or pods in different clusters match, requests from other pods in other clusters may mistakenly fall under the Istio’s rules. The intersection of subnets of services and pods is not recommended (source).
Istio operates in the multi-network mode — pods from different clusters can only communicate with each other through the Istio ingress gateway. Direct communication between pods of different clusters is not supported.
General principles
- Multicluster requires mutual trust between clusters. Thereby, to use multiclustering, you have to make sure that both clusters (say, A and B) trust each other. From a technical point of view, this is achieved by a mutual exchange of root certificates.
- Istio connects directly to the API server of the neighboring cluster to gather information about its services. This Deckhouse module takes care of the corresponding communication channel.
Enabling the multicluster
Enabling the multicluster (via the istio.multicluster.enabled = true module parameter) results in the following activities:
- A proxy is added to the cluster to publish access to the API server via the standard Ingress resource:
- Access through this public address is secured by authorization based on Bearer tokens signed with trusted keys. Deckhouse automatically exchanges trusted public keys during the mutual configuration of the multicluster.
- The proxy itself has read-only access to a limited set of resources.
- A service gets added to the cluster that exports the following cluster metadata to the outside:
- Istio root certificate (accessible without authentication).
- The public API server address (available only for authenticated requests from neighboring clusters).
- List of public addresses of the
ingressgatewayservice (available only for authenticated requests from neighboring clusters). - Server public keys to authenticate requests to API server and to private metadata (see above).
Managing the multicluster
To create a multicluster, you need to create a set of IstioMulticluster resources in each cluster that describe all the other clusters.
In case of issues when working with a multi-cluster, it is necessary to check in each cluster:
- The status of the
IstioMultiClusterresources. To do this, run the commandd8 k describe istiomulticluster cluster-name. It is important that the resource status showsRoot CAand that thePublic Last Fetch Timestampfield has a recent timestamp. - The
Ingress Gatewaysfield of theIstioMultiClusterresource should contain the IP address of the second cluster’sIngressGateway. - Using the
istioctlutility (how to install…):
istioctl remote-clusters -i d8-istio
NAME SECRET STATUS ISTIOD
cluster-b d8-istio/istio-remote-secret-cluster-b synced istiod-v1x21-5c57d85b54-k8pl7
Estimating overhead
Using Istio will incur additional resource costs for both control-plane (istiod controller) and data-plane (istio-sidecars).
control-plane
The istiod controller continuously monitors the cluster configuration, compiles the settings for the istio-sidecars and distributes them over the network. Accordingly, the more applications and their instances, the more services, and the more frequently this configuration changes, the more computational resources are required and the greater the load on the network. Two approaches are supported to reduce the load on controller instances:
- horizontal scaling (module configuration
controlPlane.replicasManagement) — the more controller instances, the fewer instances of istio-sidecars to serve for each controller and the less CPU and network load. - data-plane segmentation using the Sidecar resource (recommended approach) — the smaller the scope of an individual istio-sidecar, the less data in the data-plane needs to be updated and the less CPU and network overhead.
A rough estimate of overhead for a control-plane instance that serves 1000 services and 2000 istio-sidecars is 1 vCPU and 1.5 GB RAM.
data-plane
The consumption of data-plane resources (istio-sidecar) is affected by many factors:
- number of connections,
- the intensity of requests,
- size of requests and responses,
- protocol (HTTP/TCP),
- number of CPU cores,
- complexity of Service Mesh configuration.
A rough estimate of the overhead for an istio-sidecar instance is 0.5 vCPU for 1000 requests/sec and 50 MB RAM. istio-sidecars also increase latency in network requests — about 2.5ms per request.
Third-party components
List of third-party software used in the istio module: