Available in editions: CE, BE, SE, SE+, EE
Vertical Pod Autoscaler (VPA) is an infrastructure service that allows you to avoid setting exact resource requests for a container if their values are not known in advance. VPA can automatically adjust the CPU and memory reservations (providing that the corresponding mode is enabled) based on the actual resource consumption (as shown by the Prometheus data). Also, VPA can recommend values for resource requests and limits without updating them automatically.
VPA has the following operating modes:
"Auto"(default) — currently theAutoandRecreatemodes do the same thing. However, when Pod in-place resource update appears in Kubernetes, this mode will do exactly that."Recreate"— the mode allows VPA to change resources of running pods (restart them while running). In case of one pod running (replicas: 1), this will lead to the service being unavailable during the restart. In this mode, VPA does not recreate pods that were created without a controller."Initial"— VPA modifies Pod resources only when Pods are started (but not during operation)."Off"— VPA does not take any action to update the resource requests for the running containers. In this case, if VPA is running in this mode, you can see what resource values it recommends (kubectl describe vpa)
VPA limitations:
- Updating the resources of running Pods is currently experimental. The Pod is recreated each time VPA updates its
resource requests. The Pod can be scheduled to another node. - VPA should not be used concurrently with CPU and memory-based HPA. However, you can use VPA together with HPA for custom/external metrics.
- VPA notices almost all
out-of-memoryevents, but that does not guarantee its response. - VPA performance has not been tested for huge clusters.
- VPA recommendations may exceed the available resources in the cluster. That can lead to Pods becoming Pending.
- Using multiple VPAs for the same Pod can lead to undefined behavior.
- If VPA is deleted or “turned off” (the
Offmode), the changes made by VPA earlier are not reset (the most recent value set is kept). It may lead to confusion due to the difference between resource values in Helm/controller and the actual resources of Pods (it may be perceived as if they “came from out of nowhere”).
We highly recommend using Pod Disruption Budget with VPA.
Grafana dashboard
Displayed on dashboards:
Main / Namespace,Main / Namespace / Controller,Main / Namespace / Controller / Pod— theVPA typecolumn shows the value ofupdatePolicy.updateMode;Main / Namespaces— theVPA %column shows the percentage of VPA-enabled Pods.
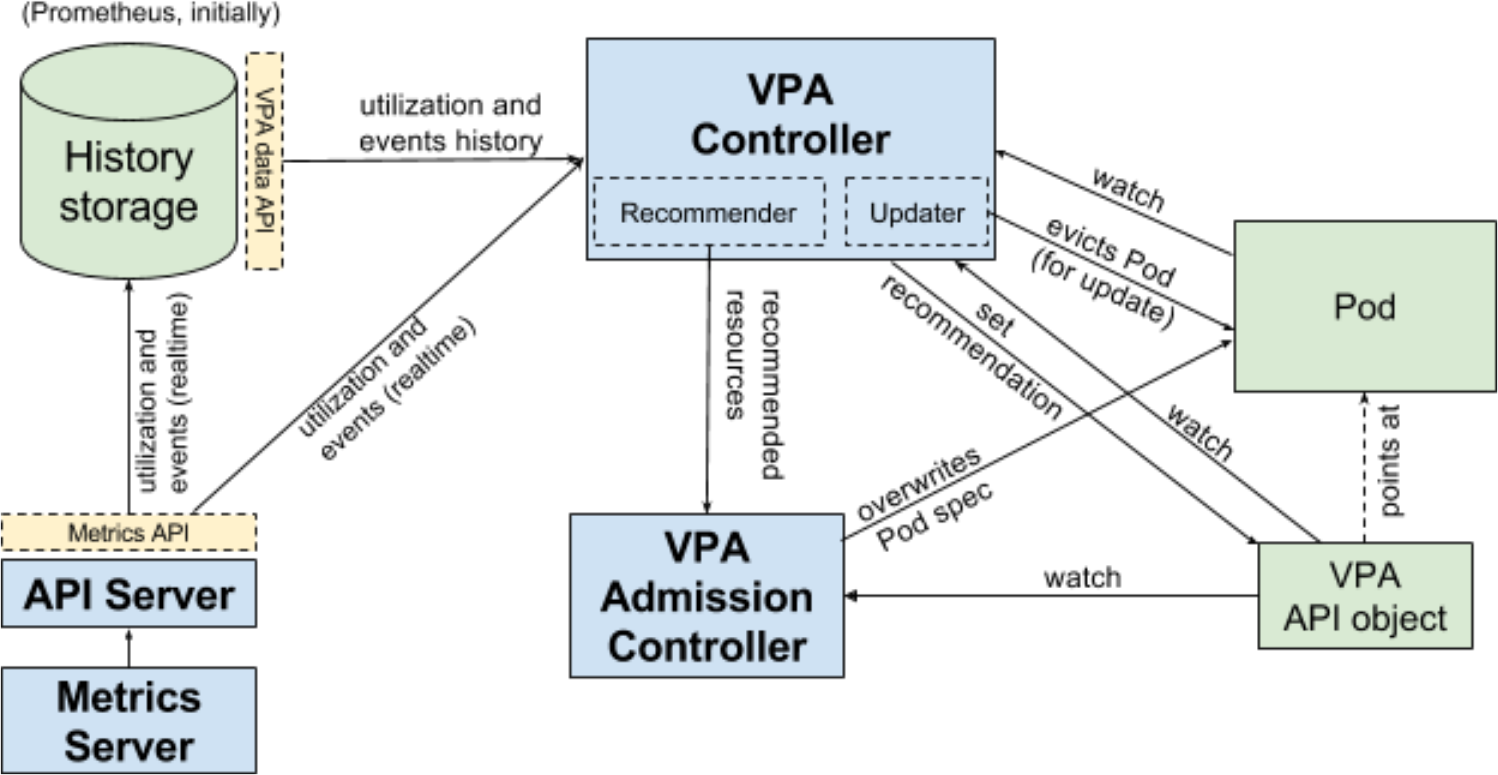
Vertical Pod Autoscaler Architecture
VPA consists of 3 components:
Recommender— this component monitors the current resource consumption (by making requests to the Metrics API implemented in theprometheus-metrics-adaptermodule) as well as consumption history (by making requests to Trickster caching proxy). As its name suggests, the component provides CPU and memory recommendations for containers.Updater— this component checks if the Pods have correct resources set and, if not, kills them so that they can be recreated by their controllers with the updated resource requests.Admission Plugin— this component sets the correct resource requests on new Pods (either just created or recreated by their controller due to Updater’s activity).
When the Updater component changes resource values, Pods are evicted using the Eviction API. Thus, the Pod Disruption Budget is taken into account for the Pods being updated.