Introduction
This guide is intended for users of Deckhouse Virtualization Platform (DVP) and describes how to create and modify resources that are available for creation in projects and cluster namespaces.
Quick start on creating a VM
Example of creating a virtual machine with Ubuntu 24.04.
-
Create a virtual machine image from an external source:
d8 k apply -f - <<EOF apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualImage metadata: name: ubuntu spec: storage: ContainerRegistry dataSource: type: HTTP http: url: https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img EOFHow to create a virtual machine image from an external source in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Disk Images” section.
- Click “Create Image”.
- Select “Load data from link (HTTP)” from the list.
- In the form that opens, enter
ubuntuin the “Image Name” field. - Select
ContainerRegistryin the “Storage” field. - In the “URL” field, paste
https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img. - Click the “Create” button.
- The image status is displayed at the top left, under the image name.
-
Create a virtual machine disk from the image created in the previous step (Caution: Make sure that the default StorageClass is present on the system before creating it):
d8 k apply -f - <<EOF apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualDisk metadata: name: linux-disk spec: dataSource: type: ObjectRef objectRef: kind: VirtualImage name: ubuntu EOFHow to create a virtual machine disk from the image created in the previous step in the web interface (this step can be skipped and performed when creating a VM):
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” section → “VM Disks”.
- Click “Create Disk”.
- In the form that opens, enter
linux-diskin the “Disk Name” field. - In the “Source” field, make sure that the “Project” checkbox is selected.
- Select
ubuntufrom the drop-down list - In the “Size” field, you can change the size to a larger one, for example,
5Gi. - In the “StorageClass Name” field, you can select StorageClass or leave the default selection.
- Click the “Create” button.
- The disk status is displayed at the top left, under the disk name.
Remember, if your StorageClass has the WaitForFirstConsumer setting, the disk will wait for a VM to be created with that disk. In this case, the disk status will be “CREATING 0%,” but the disk will already be selectable when creating a VM, see the disks section.
-
Creating a virtual machine:
The example uses the cloud-init script to create a cloud user with the cloud password generated as follows:
mkpasswd --method=SHA-512 --rounds=4096You can change the user name and password in this section:
users: - name: cloud passwd: $6$rounds=4096$G5VKZ1CVH5Ltj4wo$g.O5RgxYz64ScD5Ach5jeHS.Nm/SRys1JayngA269wjs/LrEJJAZXCIkc1010PZqhuOaQlANDVpIoeabvKK4j1Create a virtual machine from the following specification:
d8 k apply -f - <<'EOF' apiVersion: virtualization.deckhouse.io/v1alpha2 kind: VirtualMachine metadata: name: linux-vm spec: virtualMachineClassName: generic cpu: cores: 1 memory: size: 1Gi provisioning: type: UserData userData: | #cloud-config ssh_pwauth: True users: - name: cloud passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/" shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: False blockDeviceRefs: - kind: VirtualDisk name: linux-disk EOFHow to create a virtual machine in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Click “Create”.
- In the form that opens, enter
linux-vmin the “Name” field. - In the “Machine Parameters” section, you can leave the settings at their default values.
- In the “Disks and Images” section, in the “Boot Disks” subsection, click “Add”.
If you have already created a disk:
- In the form that opens, click “Choose from existing”.
- Select the
linux-diskdisk from the list.
If you have not created a disk:
- In the form that opens, click “Create new disk””
- In the “Name” field, enter
linux-disk. - In the “Source” field, click the arrow to expand the list and make sure that the “Project” checkbox is selected.
- Select
ubuntufrom the drop-down list. - In the “Size” field, you can change the size to a larger one, for example,
5Gi. - In the “Storage Class” field, you can select StorageClass or leave the default selection.
-
Click the “Create and add” button.
- Scroll down to the “Additional parameters” section.
- Enable the “Cloud-init” switch.
- Enter your data in the field that appears:
#cloud-config ssh_pwauth: True users: - name: cloud passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/" shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: False- Click the “Create” button.
- The VM status is displayed at the top left, under its name.
Useful links:
-
Verify with the command that the image and disk have been created and the virtual machine is running. Resources are not created instantly, so you will need to wait a while before they are ready.
d8 k get vi,vd,vmExample output:
NAME PHASE CDROM PROGRESS AGE virtualimage.virtualization.deckhouse.io/ubuntu Ready false 100% # NAME PHASE CAPACITY AGE virtualdisk.virtualization.deckhouse.io/linux-disk Ready 300Mi 7h40m # NAME PHASE NODE IPADDRESS AGE virtualmachine.virtualization.deckhouse.io/linux-vm Running virtlab-pt-2 10.66.10.2 7h46m -
Connect to the virtual machine using the console (press
Ctrl+]to exit the console):d8 v console linux-vmExample output:
Successfully connected to linux-vm console. The escape sequence is ^] # linux-vm login: cloud Password: cloud ... cloud@linux-vm:~$How to connect to a virtual machine using the console in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- In the form that opens, go to the “TTY” tab.
- Go to the console window that opens. Here you can connect to the VM.
-
Use the following commands to delete previously created resources:
d8 k delete vm linux-vm d8 k delete vd linux-disk d8 k delete vi ubuntu
Virtual machines
The VirtualMachine resource is used to create a virtual machine, its parameters allow you to configure:
- Virtual machine class
- Resources required for virtual machine operation (processor, memory, disks and images).
- Rules of virtual machine placement on cluster nodes.
- Bootloader settings and optimal parameters for the guest OS.
- Virtual machine startup policy and policy for applying changes.
- Initial configuration scenarios (cloud-init).
- List of block devices.
The full description of virtual machine configuration parameters can be found at link
Creating a virtual machine
Below is an example of a simple virtual machine configuration running Ubuntu OS 24.04. The example uses the initial virtual machine initialization script (cloud-init), which installs the qemu-guest-agent guest agent and the nginx service, and creates the cloud user with the cloud password:
The password in the example was generated using the command mkpasswd --method=SHA-512 --rounds=4096 -S saltsalt and you can change it to your own if necessary:
Create a virtual machine with the disk created previously:
d8 k apply -f - <<'EOF'
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachine
metadata:
name: linux-vm
spec:
# VM class name.
virtualMachineClassName: generic
# Block of scripts for the initial initialization of the VM.
provisioning:
type: UserData
# Example cloud-init script to create cloud user with cloud password and install qemu-guest-agent service and nginx service.
userData: |
#cloud-config
package_update: true
packages:
- nginx
- qemu-guest-agent
runcmd:
- systemctl daemon-reload
- systemctl enable --now nginx.service
- systemctl enable --now qemu-guest-agent.service
ssh_pwauth: True
users:
- name: cloud
passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/"
shell: /bin/bash
sudo: ALL=(ALL) NOPASSWD:ALL
lock_passwd: False
final_message: "The system is finally up, after $UPTIME seconds"
# VM resource settings.
cpu:
# Number of CPU cores.
cores: 1
# Request 10% of the CPU time of one physical core.
coreFraction: 10%
memory:
# Amount of RAM.
size: 1Gi
# List of disks and images used in the VM.
blockDeviceRefs:
# The order of disks and images in this block determines the boot priority.
- kind: VirtualDisk
name: linux-vm-root
EOF
Check the state of the virtual machine after creation:
d8 k get vm linux-vm
Example output:
NAME PHASE NODE IPADDRESS AGE
linux-vm Running virtlab-pt-2 10.66.10.12 11m
After creation, the virtual machine will automatically get an IP address from the range specified in the module settings (virtualMachineCIDRs block).
How to create a virtual machine in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Click “Create”.
- In the form that opens, enter
linux-vmin the “Name” field. - In the “Machine Parameters” section, set
1in the “Cores” field. - In the “Machine Parameters” section, set
10%in the “CPU Share” field. - In the “Machine Parameters” section, set
1Giin the “Size” field. - In the “Disks and Images” section, in the “Boot Disks” subsection, click “Add”.
- In the form that opens, click “Choose from existing”.
- Select the
linux-vm-rootdisk from the list. - Scroll down to the “Additional Parameters” section.
- Enable the “Cloud-init” switch.
-
Enter your data in the field that appears:
#cloud-config package_update: true packages: - nginx - qemu-guest-agent runcmd: - systemctl daemon-reload - systemctl enable --now nginx.service - systemctl enable --now qemu-guest-agent.service ssh_pwauth: True users: - name: cloud passwd: "$6$rounds=4096$saltsalt$fPmUsbjAuA7mnQNTajQM6ClhesyG0.yyQhvahas02ejfMAq1ykBo1RquzS0R6GgdIDlvS.kbUwDablGZKZcTP/" shell: /bin/bash sudo: ALL=(ALL) NOPASSWD:ALL lock_passwd: False final_message: "The system is finally up, after $UPTIME seconds" - Click the “Create” button.
- The VM status is displayed at the top left, under its name.
Virtual Machine Life Cycle
A virtual machine (VM) goes through several phases in its existence, from creation to deletion. These stages are called phases and reflect the current state of the VM. To understand what is happening with the VM, you should check its status (.status.phase field), and for more detailed information - .status.conditions block. All the main phases of the VM life cycle, their meaning and peculiarities are described below.
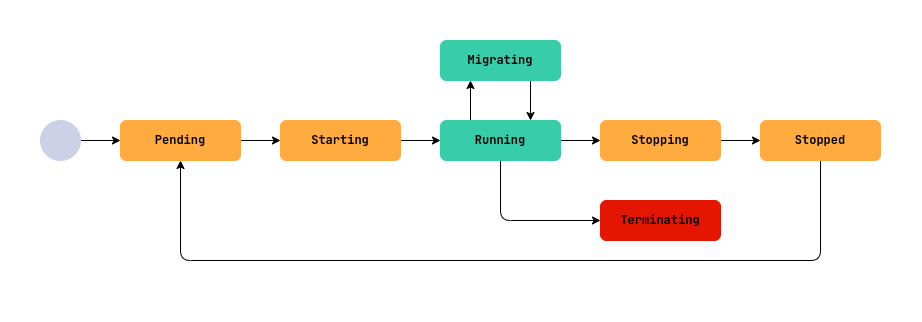
-
Pending: Waiting for resources to be readyA VM has just been created, restarted or started after a shutdown and is waiting for the necessary resources (disks, images, ip addresses, etc.) to be ready.
- Possible problems:
- Dependent resources are not ready: disks, images, VM classes, secret with initial configuration script, etc.
-
Diagnostics: In
.status.conditionsyou should pay attention to*Readyconditions. By them you can determine what is blocking the transition to the next phase, for example, waiting for disks to be ready (BlockDevicesReady) or VM class (VirtualMachineClassReady).d8 k get vm <vm-name> -o json | jq '.status.conditions[] | select(.type | test(".*Ready"))'
- Possible problems:
-
Starting: Starting the virtual machineAll dependent VM resources are ready and the system is attempting to start the VM on one of the cluster nodes.
- Possible problems:
- There is no suitable node to start.
- There is not enough CPU or memory on suitable nodes.
- Namespace or project quotas have been exceeded.
- Diagnostics:
-
If the startup is delayed, check
.status.conditions, thetype: Runningconditiond8 k get vm <vm-name> -o json | jq '.status.conditions[] | select(.type=="Running")'
-
- Possible problems:
-
Running: The virtual machine is runningThe VM is successfully started and running.
- Features:
- When qemu-guest-agent is installed in the guest system, the
AgentReadycondition will be true and.status.guestOSInfowill display information about the running guest OS.- The
type: FirmwareUpToDate, status: Falsecondition informs that the VM firmware needs to be updated. - Condition
type: ConfigurationApplied, status: Falseinforms that the VM configuration is not applied to the running VM. - The
type: SizingPolicyMatched, status: Falsecondition informs that the VM resource configuration does not match the sizing policy requirements for the VirtualMachineClass being used and requires that these settings be brought into compliance otherwise new changes to the VM configuration cannot be saved. - The
type: AwaitingRestartToApplyConfiguration, status: Truecondition displays information about the need to manually reboot the VM because some configuration changes cannot be applied without rebooting the VM.
- The
- Possible problems:
- An internal failure in the VM or hypervisor.
- Diagnosis:
-
Check
.status.conditions, conditiontype: Running.d8 k get vm <vm-name> -o json | jq '.status.conditions[] | select(.type=="Running")'
-
- When qemu-guest-agent is installed in the guest system, the
- Features:
-
Stopping: The VM is stopped or rebooted. -
Stopped: The VM is stopped and is not consuming computational resources -
Terminating: the VM is deleted.This phase is irreversible. All resources associated with the VM are released, but are not automatically deleted.
-
Migrating: Live migration of a VM.The VM is migrated to another node in the cluster (live migration).
- Features:
- The
type: Migratablecondition indicates whether the VM can be migrated.
- The
- Possible issues:
- Incompatibility of processor instructions (when using host or host-passthrough processor types).
- Difference in kernel versions on hypervisor nodes.
- Not enough CPU or memory on eligible nodes.
- Namespace or project quotas have been exceeded.
- Diagnostics:
-
Check the
.status.conditionsconditiontype: Migratingas well as the.status.migrationStateblockd8 k get vm <vm-name> -o json | jq '.status | {condition: .conditions[] | select(.type=="Migrating"), migrationState}'
-
- Features:
The type: SizingPolicyMatched, status: False condition indicates that the resource configuration does not comply with the sizing policy of the VirtualMachineClass being used. If the policy is violated, it is impossible to save VM parameters without making the resources conform to the policy.
Conditions display information about the state of the VM, as well as on problems that arise. You can understand what is wrong with the VM by analyzing them:
d8 k get vm fedora -o json | jq '.status.conditions[] | select(.message != "")'
Configuring CPU and coreFraction
When creating a virtual machine, you can configure how much CPU resources it will use using the cores and coreFraction parameters.
The cores parameter specifies the number of virtual CPU cores allocated to the VM.
The coreFraction parameter specifies the guaranteed minimum share of processing power allocated to each core.
Available coreFraction values may be defined in the VirtualMachineClass resource for a given range of cores (cores), in which case only those values may be used.
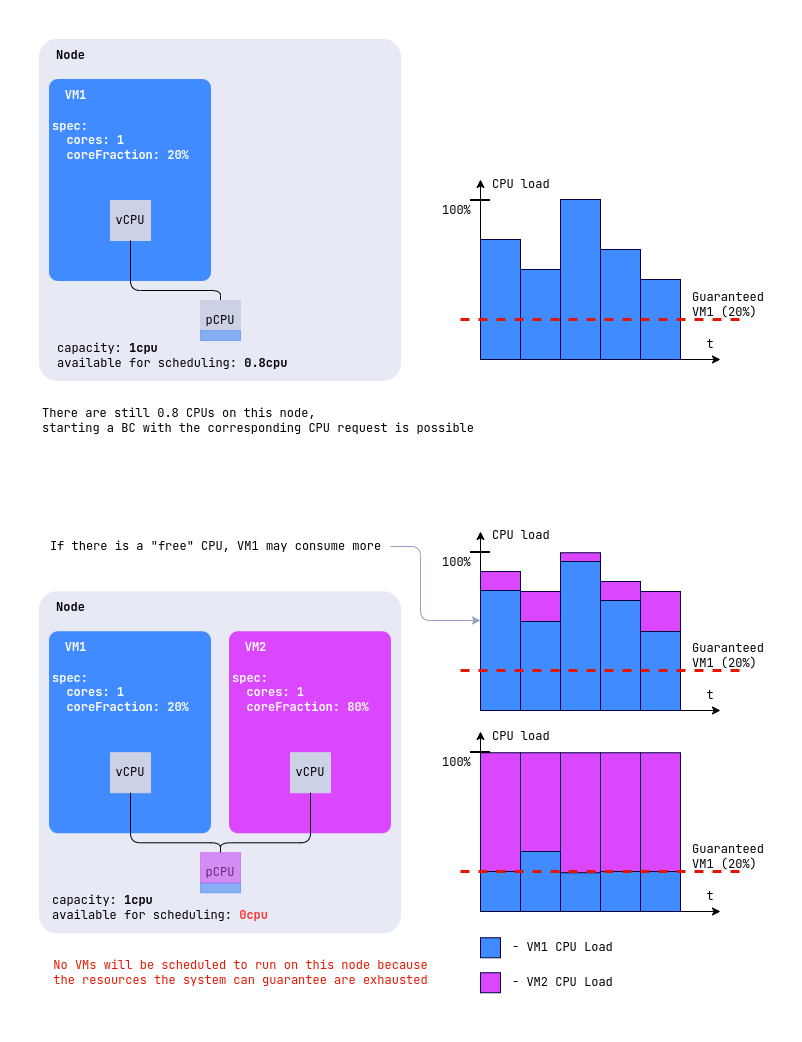
For example, if you specify cores: 2, the VM will be allocated two virtual cores corresponding to the two physical cores of the hypervisor.
If coreFraction: 20%, the VM is guaranteed to receive at least 20% of the processing power of each core, regardless of the hypervisor node utilization. At the same time, if there are free resources on the node, the VM can use up to 100% of each core’s power to maximize performance.
Thus, the VM is guaranteed to receive 0.2 CPU of the processing power of each physical core and can utilize up to 100% of the power of two cores (2 CPUs) if there are idle resources on the node.
If the coreFraction parameter is not defined, each VM virtual core is allocated 100% of the physical hypervisor CPU core.
Let’s look at an example configuration:
spec:
cpu:
cores: 2
coreFraction: 10%
This approach allows for stable VM performance even under high load under conditions of CPU resource oversubscription, where more cores are allocated to virtual machines than are available on the hypervisor.
The cores and coreFraction parameters are taken into account when planning the placement of VMs on nodes. The guaranteed capacity (minimum fraction of each core) is considered when selecting a node so that it can provide the required performance for all VMs. If a node does not have sufficient resources to fulfill the guarantees, the VM will not run on that node.
Visualization on the example of virtual machines with the following CPU configurations, when placed on the same node:
VM1:
spec:
cpu:
cores: 1
coreFraction: 20%
VM2:
spec:
cpu:
cores: 1
coreFraction: 80%
Virtual machine resource configuration and sizing policy
The sizing policy in VirtualMachineClass, defined in the .spec.sizingPolicies section, defines the rules for configuring virtual machine resources, including the number of cores, memory size, and core utilization fraction (coreFraction). This policy is not mandatory. If it is not present for a VM, you can specify arbitrary values for resources without strict requirements. However, if a sizing policy is present, the VM configuration must strictly comply with it. Otherwise, it will not be possible to save the configuration.
The policy divides the number of cores (cores) into ranges, such as 1-4 cores or 5-8 cores. For each range, it specifies how much memory can be allocated (memory) per core and/or what coreFraction values are allowed.
If the VM configuration (cores, memory, or coreFraction) does not match the policy, the VM status will show the condition type: SizingPolicyMatched, status: False.
If you change the policy in the VirtualMachineClass, you may need to update the configuration of existing VMs to comply with the new policy. Virtual machines that do not meet the requirements of the new policy will continue to run, but any changes to their configuration cannot be saved until they comply with the new conditions.
For example:
spec:
sizingPolicies:
- cores:
min: 1
max: 4
memory:
min: 1Gi
max: 8Gi
coreFractions: [5, 10, 20, 50, 100]
- cores:
min: 5
max: 8
memory:
min: 5Gi
max: 16Gi
coreFractions: [20, 50, 100]
If the VM uses 2 cores, it falls in the range of 1-4 cores. Then memory can be selected from 1 GB to 8 GB, and coreFraction is only 5%, 10%, 20%, 50%, or 100%. For 6 cores, the range is 5-8 cores, where memory is from 5GB to 16GB and coreFraction is 20%, 50% or 100%.
In addition to VM sizing, the policy also allows you to implement the desired maximum oversubscription for VMs.
For example, by specifying coreFraction: 20% in the policy, you guarantee any VM at least 20% of the CPU compute resources, which would effectively define a maximum possible oversubscription of 5:1.
Automatic CPU topology configuration
The CPU topology of a virtual machine (VM) determines how the CPU cores are allocated across sockets. This is important to ensure optimal performance and compatibility with applications that may depend on the CPU configuration. In the VM configuration, you specify only the total number of processor cores, and the topology (the number of sockets and cores in each socket) is automatically calculated based on this value.
The number of processor cores is specified in the VM configuration as follows:
spec:
cpu:
cores: 1
Next, the system automatically determines the topology depending on the specified number of cores. The calculation rules depend on the range of the number of cores and are described below.
- If the number of cores is between 1 and 16 (1 ≤
.spec.cpu.cores≤ 16):- 1 socket is used.
- The number of cores in the socket is equal to the specified value.
- Change step: 1 (you can increase or decrease the number of cores one at a time).
- Valid values: any integer from 1 to 16 inclusive.
- Example: If
.spec.cpu.cores= 8, topology: 1 socket with 8 cores.
- If the number of cores is from 17 to 32 (16 <
.spec.cpu.cores≤ 32):- 2 sockets are used.
- Cores are evenly distributed between sockets (the number of cores in each socket is the same).
- Change step: 2 (total number of cores must be even).
- Allowed values: 18, 20, 22, 24, 26, 28, 30, 32.
- Limitations: minimum 9 cores per socket, maximum 16 cores per socket.
- Example: If
.spec.cpu.cores= 20, topology: 2 sockets with 10 cores each.
- If the number of cores is between 33 and 64 (32 <
.spec.cpu.cores≤ 64):- 4 sockets are used.
- Cores are evenly distributed among the sockets.
- Step change: 4 (the total number of cores must be a multiple of 4).
- Allowed values: 36, 40, 44, 48, 52, 56, 60, 64.
- Limitations: minimum 9 cores per socket, maximum 16 cores per socket.
- Example: If
.spec.cpu.cores= 40, topology: 4 sockets with 10 cores each.
- If the number of cores is greater than 64 (
.spec.cpu.cores> 64):- 8 sockets are used.
- Cores are evenly distributed among the sockets.
- Step change: 8 (the total number of cores must be a multiple of 8).
- Valid values: 72, 80, 88, 96, and so on up to 248.
- Limitations: minimum 9 cores per socket.
- Example: If
.spec.cpu.cores= 80, topology: 8 sockets with 10 cores each.
The change step indicates by how much the total number of cores can be increased or decreased so that they are evenly distributed across the sockets.
The maximum possible number of cores is 248.
Summary table by spec.cpu.cores range:
| Cores range | Number of sockets | Change step | Minimum cores per socket | Maximum cores per socket |
|---|---|---|---|---|
1 ≤ cores ≤ 16 |
1 | 1 | 1 | 16 |
16 < cores ≤ 32 |
2 | 2 | 9 | 16 |
32 < cores ≤ 64 |
4 | 4 | 9 | 16 |
64 < cores ≤ 248 |
8 | 8 | 9 | 16 |
Memory overhead does not depend on the maximum possible vCPU topology; it is calculated from actively used cores: (sockets × cores per socket × threads per core) × 8 MiB per logical CPU.
Example: with spec.cpu.cores: 20, the status shows a topology of two sockets with 10 cores each:
spec:
cpu:
cores: 20
# ...
status:
resources:
cpu:
topology:
coresPerSocket: 10
sockets: 2
The current VM topology (number of sockets and cores in each socket) is displayed in the VM status in the following format:
status:
resources:
cpu:
coreFraction: 10%
cores: 1
requestedCores: "1"
runtimeOverhead: "0"
topology:
sockets: 1
coresPerSocket: 1
OS type and bootloader configuration
The osType parameter determines the operating system type and applies an optimal set of virtual devices and parameters for correct VM operation.
Supported values:
Generic(default): For Linux and other operating systems. Uses standard virtual device configuration.Windows: For Microsoft Windows family operating systems. Automatically enables Hyper-V features, TPM device, and other settings optimized for Windows.
The TPM device provided to the virtual machine is not persistent (TPM emulation in memory). This means that when the VM is rebooted or migrated, the TPM state is reset. It is recommended to consider this limitation when planning to use Windows security features that depend on TPM.
The bootloader parameter determines the bootloader type for the virtual machine:
BIOS(default): Use legacy BIOS.EFI: Use Unified Extensible Firmware Interface (UEFI/EFI).EFIWithSecureBoot: Use UEFI/EFI with Secure Boot support.
Example configuration for a Windows virtual machine:
spec:
osType: Windows
bootloader: EFI
# other parameters...
Example configuration for a Linux virtual machine (default values can be omitted):
spec:
osType: Generic
bootloader: BIOS
# other parameters...
For most modern Linux distributions, it is recommended to use bootloader: EFI. For Windows, bootloader: EFI or bootloader: EFIWithSecureBoot is usually required.
The enableParavirtualization parameter controls the use of the virtio bus for connecting virtual devices of the VM:
true(default) — uses thevirtiobus for disks, network interfaces, and other devices, providing better performance.false— uses standard device emulation (SATA for disks, e1000e for network interfaces), which may be necessary for compatibility with older operating systems.
To use paravirtualization mode (virtio), some operating systems require installing the corresponding drivers. If drivers are not installed, the VM may fail to boot or devices may not work correctly.
Example configuration with paravirtualization disabled:
spec:
enableParavirtualization: false
# other parameters...
Initialization scripts
Initialization scripts are used for the initial configuration of a virtual machine when it is started.
The following initialization scripts are supported:
Cloud-Init
Cloud-Init is a tool for automatically configuring virtual machines on first boot. It allows you to perform a wide range of configuration tasks without manual intervention.
Cloud-Init configuration is written in YAML format and must start with the #cloud-config header at the beginning of the configuration block. For information about other possible headers and their purpose, see the official Cloud-Init documentation.
The main capabilities of Cloud-Init include:
- Creating users, setting passwords, and adding SSH keys for access.
- Automatically installing necessary software on first boot.
- Running arbitrary commands and scripts for system configuration.
- Automatically starting and enabling system services (for example,
qemu-guest-agent).
Typical usage scenarios
-
Adding an SSH key for a pre-installed user that may already be present in the cloud image (for example, the
ubuntuuser in official Ubuntu images). The name of such a user depends on the image. Check the documentation for your distribution.#cloud-config ssh_authorized_keys: - ssh-ed25519 AAAAB3NzaC1yc2EAAAADAQABAAABAQD... your-public-key ... -
Creating a user with a password and SSH key:
#cloud-config users: - name: cloud passwd: "$6$rounds=4096$saltsalt$..." lock_passwd: false sudo: ALL=(ALL) NOPASSWD:ALL shell: /bin/bash ssh-authorized-keys: - ssh-ed25519 AAAAB3NzaC1yc2EAAAADAQABAAABAQD... your-public-key ... ssh_pwauth: TrueTo generate a password hash, use the command
mkpasswd --method=SHA-512 --rounds=4096. -
Installing packages and services:
#cloud-config package_update: true packages: - nginx - qemu-guest-agent runcmd: - systemctl daemon-reload - systemctl enable --now nginx.service - systemctl enable --now qemu-guest-agent.service
Using Cloud-Init
The Cloud-Init script can be embedded directly into the virtual machine specification, but its size is limited to a maximum of 2048 bytes:
spec:
provisioning:
type: UserData
userData: |
#cloud-config
package_update: true
...
For longer scenarios and/or when private data is involved, the script for initial initialization of the virtual machine can be created in a Secret resource. An example of a Secret with a Cloud-Init script is shown below:
apiVersion: v1
kind: Secret
metadata:
name: cloud-init-example
data:
userData: <base64 data>
type: provisioning.virtualization.deckhouse.io/cloud-init
A fragment of the virtual machine configuration when using the Cloud-Init initialization script stored in a Secret:
spec:
provisioning:
type: UserDataRef
userDataRef:
kind: Secret
name: cloud-init-example
The value of the .data.userData field must be Base64 encoded. To encode it, you can use the base64 -w 0 command or echo -n "content" | base64.
Sysprep
When configuring virtual machines running Windows using Sysprep, only the Secret-based option is supported.
An example of a Secret with a Sysprep script is shown below:
apiVersion: v1
kind: Secret
metadata:
name: sysprep-example
data:
unattend.xml: <base64 data>
type: provisioning.virtualization.deckhouse.io/sysprep
The value of the .data.unattend.xml field must be Base64 encoded. To encode, you can use the command base64 -w 0 or echo -n "content" | base64.
A fragment of the virtual machine configuration using the Sysprep initialization script in a Secret:
spec:
provisioning:
type: SysprepRef
sysprepRef:
kind: Secret
name: sysprep-example
Guest OS agent
To improve VM management efficiency, it is recommended to install the QEMU Guest Agent, a tool that enables communication between the hypervisor and the operating system inside the VM.
How will the agent help?
- It will provide consistent snapshots of disks and VMs.
-
It will provide information about the running OS, which will be reflected in the status of the VM. Example:
status: guestOSInfo: id: fedora kernelRelease: 6.11.4-301.fc41.x86_64 kernelVersion: '#1 SMP PREEMPT_DYNAMIC Sun Oct 20 15:02:33 UTC 2024' machine: x86_64 name: Fedora Linux prettyName: Fedora Linux 41 (Cloud Edition) version: 41 (Cloud Edition) versionId: "41" -
Will allow tracking that the OS has actually booted:
d8 k get vm -o wideExample output (see
AGENTcolumn):NAME PHASE CORES COREFRACTION MEMORY NEED RESTART AGENT MIGRATABLE NODE IPADDRESS AGE fedora Running 6 5% 8000Mi False True True virtlab-pt-1 10.66.10.1 5d21h
How to install QEMU Guest Agent:
For Debian-based OS:
sudo apt install qemu-guest-agent
For CentOS-based OS:
sudo yum install qemu-guest-agent
Starting the agent service:
sudo systemctl enable --now qemu-guest-agent
You can automate the installation of the agent for Linux OS using a cloud-init initialization script. Below is an example snippet of such a script to install qemu-guest-agent:
#cloud-config
package_update: true
packages:
- qemu-guest-agent
runcmd:
- systemctl enable --now qemu-guest-agent.service
QEMU Guest Agent does not require additional configuration after installation. However, to ensure application-level snapshot consistency (without stopping services), you can add scripts that are executed automatically in the guest OS before and after filesystem freeze and thaw operations. The scripts must be executable and placed in a special directory, whose path depends on the Linux distribution in use:
Connecting to a virtual machine
The following methods are available for connecting to the virtual machine:
- remote management protocol (such as SSH), which must be preconfigured on the virtual machine.
- serial console.
- VNC protocol.
An example of connecting to a virtual machine using a serial console:
d8 v console linux-vm
Example output:
Successfully connected to linux-vm console. The escape sequence is ^]
#
linux-vm login: cloud
Password: cloud
Press Ctrl+] to finalize the serial console.
The serial console does not support automatic terminal resizing. If full-screen applications or text editors are displayed incorrectly, run the following command after you log in:
stty rows <number_of_rows> cols <number_of_columns>
For example: stty rows 50 cols 200
If the xterm package is installed on the system, you can also use the resize command.
Example command for connecting via VNC:
d8 v vnc linux-vm
Example command for connecting via SSH.
d8 v ssh cloud@linux-vm --local-ssh
How to connect to a virtual machine in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- In the form that opens, go to the “TTY” tab to work with the serial console.
- In the form that opens, go to the “VNC” tab to connect via VNC.
- Go to the window that opens. Here you can connect to the VM.
Virtual machine startup policy and virtual machine state management
The virtual machine startup policy is intended for automated virtual machine state management. It is defined as the .spec.runPolicy parameter in the virtual machine specification. The following policies are supported:
AlwaysOnUnlessStoppedManually(default): After creation, the VM is always in a running state. In case of failures the VM operation is restored automatically. It is possible to stop the VM only by calling thed8 v stopcommand or creating a corresponding operation.AlwaysOn: After creation the VM is always in a running state, even in case of its shutdown by OS means. In case of failures the VM operation is restored automatically.Manual: After creation, the state of the VM is controlled manually by the user using commands or operations. The VM is powered off immediately after creation. To power it on, thed8 v startcommand must be executed.AlwaysOff: After creation the VM is always in the off state. There is no possibility to turn on the VM through commands/operations.
How to select a VM startup policy in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the desired VM from the list and click on its name.
- On the “Configuration” tab, scroll down to the “Additional Settings” section.
- Select the desired policy from the Startup Policy combo box.
The state of the virtual machine can be controlled using the following methods:
Creating a VirtualMachineOperation (vmop) resource.
Using the d8 utility with the corresponding subcommand.
The VirtualMachineOperation resource declaratively defines an imperative action to be performed on the virtual machine. This action is applied to the virtual machine immediately after it is created by the corresponding vmop. The action is applied to the virtual machine once.
Example operation to perform a reboot of a virtual machine named linux-vm:
d8 k create -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineOperation
metadata:
generateName: restart-linux-vm-
spec:
virtualMachineName: linux-vm
type: Restart
EOF
You can view the result of the action using the command:
d8 k get virtualmachineoperation
# or
d8 k get vmop
The same action can be performed using the d8 utility:
d8 v restart linux-vm
A list of possible operations is given in the table below:
| d8 | vmop type | Action |
|---|---|---|
d8 v stop |
Stop |
Stop VM |
d8 v start |
Start |
Start the VM |
d8 v restart |
Restart |
Restart the VM |
d8 v evict |
Evict |
Migrate the VM to another host |
How to perform the operation in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the desired virtual machine from the list and click the ellipsis button.
- In the pop-up menu, you can select possible operations for the VM.
Change virtual machine configuration
You can change the configuration of a virtual machine at any time after the VirtualMachine resource has been created. However, how these changes are applied depends on the current phase of the virtual machine and the nature of the changes made.
Changes to the virtual machine configuration can be made using the following command:
d8 k edit vm linux-vm
If the virtual machine is in a shutdown state (.status.phase: Stopped), the changes made will take effect immediately after the virtual machine is started.
If the virtual machine is running (.status.phase: Running), the way the changes are applied depends on the type of change:
| Configuration block | How changes are applied |
|---|---|
.metadata.labels |
Applies immediately and propagates to the VM pod |
.metadata.annotations |
Applies immediately and propagates to the VM pod |
.spec.liveMigrationPolicy |
Applies immediately |
.spec.runPolicy |
Applies immediately |
.spec.disruptions.restartApprovalMode |
Applies immediately |
.spec.affinity |
EE, SE+: Applies immediately, CE: Only after VM restart |
.spec.nodeSelector |
EE, SE+: Applies immediately, CE: Only after VM restart |
.spec.cpu.cores |
May apply immediately if hotplug is enabled (EE, SE+), see CPU hotplug; otherwise a restart is required. |
.spec.* |
Only after VM restart |
How to change the VM configuration in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- You are now on the “Configuration” tab, where you can make changes.
- The list of changed parameters and a warning if the VM needs to be restarted are displayed at the top of the page.
Let’s consider an example of changing the configuration of a virtual machine:
Suppose we want to change the number of processor cores. The virtual machine is currently running and using one core, which can be confirmed by connecting to it through the serial console and executing the nproc command.
d8 v ssh cloud@linux-vm --local-ssh --command "nproc"
Example output:
1
Apply the following patch to the virtual machine to change the number of cores from 1 to 2.
d8 k patch vm linux-vm --type merge -p '{"spec":{"cpu":{"cores":2}}}'
# Alternatively, apply the changes by editing the resource.
d8 k edit vm linux-vm
Example output:
# virtualmachine.virtualization.deckhouse.io/linux-vm patched
Configuration changes have been made but not yet applied to the virtual machine. Check this by re-executing:
d8 v ssh cloud@linux-vm --local-ssh --command "nproc"
Example output:
1
A restart of the virtual machine is required to apply this change. Run the following command to see the changes waiting to be applied (requiring a restart):
d8 k get vm linux-vm -o jsonpath="{.status.restartAwaitingChanges}" | jq .
Example output:
[
{
"currentValue": 1,
"desiredValue": 2,
"operation": "replace",
"path": "cpu.cores"
}
]
Run the command:
d8 k get vm linux-vm -o wide
Example output:
NAME PHASE CORES COREFRACTION MEMORY NEED RESTART AGENT MIGRATABLE NODE IPADDRESS AGE
linux-vm Running 2 100% 1Gi True True True virtlab-pt-1 10.66.10.13 5m16s
In the NEED RESTART column we see the value True, which means that a reboot is required to apply the changes.
Let’s reboot the virtual machine:
d8 v restart linux-vm
After a reboot, the changes will be applied and the .status.restartAwaitingChanges block will be empty.
Execute the command to verify:
d8 v ssh cloud@linux-vm --local-ssh --command "nproc"
Example output:
2
The default behavior is to apply changes to the virtual machine through a “manual” restart. If you want to apply the changes immediately and automatically, you need to change the change application policy:
spec:
disruptions:
restartApprovalMode: Automatic
How to perform the operation in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines””section.
- Select the required VM from the list and click on its name.
- On the “Configuration” tab, scroll down to the “Additional Settings” section.
- Enable the “Auto-apply changes” switch.
- Click on the “Save” button that appears.
CPU hotplug
CPU hotplug lets you change spec.cpu.cores for a running VM without restart when the change can be applied through live migration. Within the current CPU topology, you can both increase and decrease the number of cores.
This functionality is disabled by default.
To enable this functionality, add HotplugCPUWithLiveMigration to .spec.settings.featureGates array in the ModuleConfig/virtualization:
kind: ModuleConfig
metadata:
name: virtualization
spec:
settings:
featureGates:
- HotplugCPUWithLiveMigration
If the new .spec.cpu.cores value falls within the hotplug range for the current topology and the VM is migratable, the change is applied through live migration. If the new value requires a different CPU topology or the VM cannot be migrated, a VM restart is required. The need for restart is reflected by the AwaitingRestartToApplyConfiguration condition.
Topology calculation rules and allowed change steps for spec.cpu.cores are described in Automatic CPU topology configuration.
Guest OS specifics:
- After live migration, new vCPUs may require explicit activation inside the guest OS.
-
On Linux, added CPUs can be enabled through sysfs:
echo 1 > /sys/devices/system/cpu/cpu1/online -
To automatically enable new CPUs on Linux, configure a
udevrule. After that, added CPUs become visible incat /proc/cpuinfoandtop:cat <<'EOF' > /etc/udev/rules.d/99-hotplug-cpu.rules SUBSYSTEM=="cpu",ACTION=="add",RUN+="/bin/sh -c '[ ! -e /sys$devpath/online ] || echo 1 > /sys$devpath/online'" EOF
Limitations:
- Changing
spec.cpu.coreswithout restart is possible only within the hotplug range of the current CPU topology. - If the change requires CPU topology reconfiguration, a VM restart is required.
- When decreasing CPU count within the current topology, CPU distribution across sockets may become uneven.
Memory hotplug
Memory hotplug lets you increase spec.memory.size for a running VM without restart when the change can be applied through live migration. Decreasing memory always requires a VM restart.
This functionality is disabled by default.
To enable this functionality, add HotplugMemoryWithLiveMigration to .spec.settings.featureGates array in the ModuleConfig virtualization:
kind: ModuleConfig
metadata:
name: virtualization
spec:
settings:
featureGates:
- HotplugMemoryWithLiveMigration
If the new spec.memory.size is greater than the current value and the VM is migratable, the change is applied through live migration. If you need to shrink memory, the VM originally had less than 1 GiB of memory, or the VM cannot be migrated, a VM restart is required. The need for restart is reflected by the AwaitingRestartToApplyConfiguration condition.
Guest OS specifics:
- After live migration, newly added memory blocks may require explicit activation inside the guest OS; memory configured at VM creation does not require extra activation.
-
On Linux, added memory can be enabled through sysfs (see device names in
ls /sys/bus/memory/devices/):echo 1 > /sys/bus/memory/devices/memoryXXX/online -
To automatically enable added memory on Linux, configure a
udevrule. After that, added memory becomes visible infreeandlsmem:cat <<'EOF' > /etc/udev/rules.d/99-hotplug-memory.rules SUBSYSTEM=="memory",ACTION=="add",DEVPATH=="/devices/system/memory/memory[0-9]*", TEST=="state", ATTR{state}!="online", ATTR{state}="online" EOF
Limitations:
- Increasing memory without restart is possible only if the VM memory size is at least 1 GiB. If the VM was created with less than 1 GiB, any memory size change requires a restart.
- In the current module version, the maximum VM memory size is limited to 256 GiB.
Placement of VMs by nodes
The following methods can be used to manage the placement of virtual machines (placement parameters) across nodes:
- Simple label selection (
nodeSelector) — the basic method for selecting nodes with specified labels. - Preferred selection (
Affinity): nodeAffinity: Specifies priority nodes for placement.virtualMachineAndPodAffinity: Defines workload co-location rules for VMs or containers.
- Co-location avoidance (
AntiAffinity): virtualMachineAndPodAntiAffinity: Defines workload rules for VMs or containers to be placed on the same node.
All of the above parameters (including the .spec.nodeSelector parameter from VirtualMachineClass) are applied together when scheduling VMs. If at least one condition cannot be met, the VM will not be started. To minimize risks, we recommend:
- Creating consistent placement rules.
- Checking the compatibility of rules before applying them.
- Consider the types of conditions:
- Strict (
requiredDuringSchedulingIgnoredDuringExecution) — require strict compliance. - Soft (
preferredDuringSchedulingIgnoredDuringExecution) — allow partial compliance. - Use combinations of labels instead of single restrictions. For example, instead of required for a single label (e.g. env=prod), use several preferred conditions.
- Consider the order in which interdependent VMs are launched. When using Affinity between VMs (for example, the backend depends on the database), launch the VMs referenced by the rules first to avoid lockouts.
- Plan backup nodes for critical workloads. For VMs with strict requirements (e.g., AntiAffinity), provide backup nodes to avoid downtime in case of failure or maintenance.
- Consider existing
taintson nodes. If necessary, you can add appropriatetolerationsto the VM.
When changing placement parameters:
- If the current location of the VM meets the new requirements, it remains on the current node.
-
If the requirements are violated:
- In commercial editions: The VM is automatically moved to a suitable node using live migration.
- In the CE edition: The VM will require a reboot to apply.
How to manage VM placement parameters by nodes in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- On the “Configuration” tab, scroll down to the “Placement” section.
Tolerance to node restrictions
tolerations allow VMs to be scheduled onto nodes with taints that would otherwise block placement. This is useful when you need to run VMs on special nodes (for example, test nodes) or nodes with specific characteristics.
Example of using tolerations to allow scheduling on nodes with the node.deckhouse.io/group=:NoSchedule taint:
spec:
tolerations:
- key: "node.deckhouse.io/group"
operator: "Exists"
effect: "NoSchedule"
Each entry in tolerations must match a node taint for the VM to be scheduled onto that node.
Viewing node information (including taints) requires an appropriate role with access to cluster-level resources.
To view taints on cluster nodes, run:
d8 k get nodes -o custom-columns=NAME:.metadata.name,TAINTS:.spec.taints
For more details:
d8 k describe node <node-name>
Simple label binding (nodeSelector)
A nodeSelector is the simplest way to control the placement of virtual machines using a set of labels. It allows you to specify on which nodes virtual machines can run by selecting nodes with the desired labels.
spec:
nodeSelector:
disktype: ssd
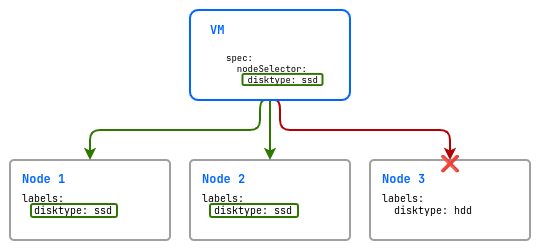
In this example, there are three nodes in the cluster: two with fast disks (disktype=ssd) and one with slow disks (disktype=hdd). The virtual machine will only be placed on nodes that have the disktype label with the value ssd.
How to perform the operation in the web interface in the Placement section:
- Click “Add” in the “Run on nodes” -> “Select nodes by labels” block.
- In the pop-up window, you can set the “Key” and “Value” of the key that corresponds to the
spec.nodeSelectorsettings. - To confirm the key parameters, click the “Enter” button.
- Click the “Save” button that appears.
Preferred Binding (Affinity)
Placement requirements can be:
- Strict (
requiredDuringSchedulingIgnoredDuringExecution) — The VM is placed only on nodes that meet the condition. - Soft (
preferredDuringSchedulingIgnoredDuringExecution) — The VM is placed on suitable nodes, if possible.
nodeAffinity: Determines on which nodes a VM can be launched using tag expressions.
Example of using nodeAffinity with a strict rule:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
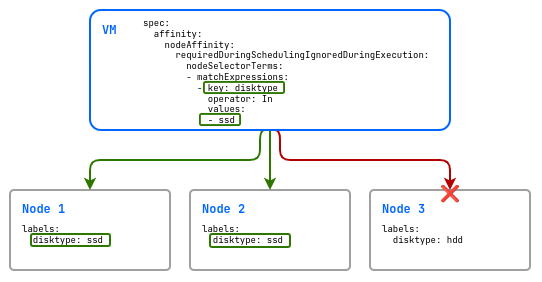
In this example, there are three nodes in the cluster, two with fast disks (disktype=ssd) and one with slow disks (disktype=hdd). The virtual machine will only be deployed on nodes that have the disktype label with the value ssd.
If you use a soft requirement (preferredDuringSchedulingIgnoredDuringExecution), then if there are no resources to start the VM on nodes with disks labeled disktype=ssd, it will be scheduled on a node with disks labeled disktype=hdd.
virtualMachineAndPodAffinity controls the placement of virtual machines relative to other virtual machines. It allows you to specify a preference for placing virtual machines on the same nodes where certain virtual machines are already running.
Example of a soft rule:
spec:
affinity:
virtualMachineAndPodAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchLabels:
server: database
topologyKey: "kubernetes.io/hostname"
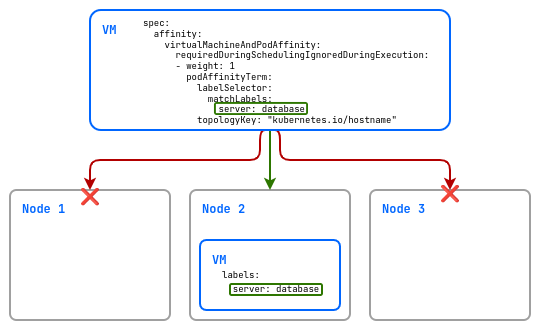
In this example, the virtual machine will be placed, if possible (since preferred is used) only on hosts that have a virtual machine with the server label and database value.
To place VMs across availability zones instead of specific nodes, set topologyKey to topology.kubernetes.io/zone (see Placing VMs by availability zones).
How to set “preferences” and “mandatories” for placing virtual machines in the web interface in the Placement section:
- Click “Add” in the “Run VM near other VMs” block.
- In the pop-up window, you can set the “Key” and “Value” of the key that corresponds to the
spec.affinity.virtualMachineAndPodAffinitysettings. - To confirm the key parameters, click the “Enter” button.
- Select one of the options “On one server” or “In one zone” that corresponds to the
topologyKeyparameter. - Click the “Save” button that appears.
Avoid co-location (AntiAffinity)
AntiAffinity is the opposite of Affinity, which allows you to specify requirements to avoid co-location of virtual machines on the same hosts. This is useful for load balancing or fault tolerance.
Placement requirements can be strict or soft:
- Strict (
requiredDuringSchedulingIgnoredDuringExecution) — The VM is scheduled only on nodes that meet the condition. - Soft (
preferredDuringSchedulingIgnoredDuringExecution) — The VM is scheduled on suitable nodes if possible.
Be careful when using strict requirements in small clusters with few nodes for VMs. If you apply virtualMachineAndPodAntiAffinity with requiredDuringSchedulingIgnoredDuringExecution, each VM replica must run on a separate node. In a cluster with limited nodes, this may cause some VMs to fail to start due to insufficient available nodes.
The terms Affinity and AntiAffinity apply only to the relationship between virtual machines. For nodes, the bindings used are called nodeAffinity. There is no separate antithesis in nodeAffinity as with virtualMachineAndPodAffinity, but you can create opposite conditions by specifying negative operators in label expressions: to emphasize the exclusion of certain nodes, you can use nodeAffinity with an operator such as NotIn.
Example of using virtualMachineAndPodAntiAffinity:
spec:
affinity:
virtualMachineAndPodAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
server: database
topologyKey: "kubernetes.io/hostname"
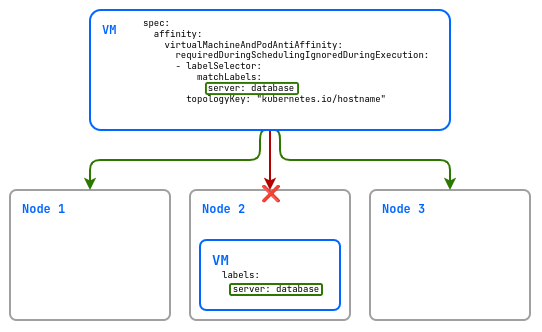
In this example, the virtual machine being created will not be placed on the same host as the virtual machine labeled server: database.
To place VMs across availability zones instead of specific nodes, set topologyKey to topology.kubernetes.io/zone (see Placing VMs by availability zones).
How to configure VM AntiAffinity on nodes in the web interface in the Placement section:
- Click “Add” in the “Identify similar VMs by labels” -> “Select labels” block.
- In the pop-up window, you can set the “Key” and “Value” of the key that corresponds to the
spec.affinity.virtualMachineAndPodAntiAffinitysettings. - To confirm the key parameters, click the “Enter” button.
- Check the boxes next to the labels you want to use in the placement settings.
- Select one of the options in the “Select options” section.
- Click the “Save” button that appears.
Placing VMs by availability zones
Availability zones must be pre-configured on cluster nodes. For this, nodes must have the topology.kubernetes.io/zone label set with the availability zone specified.
In the examples above, topologyKey: "kubernetes.io/hostname" is used, which places VMs on the same node. For placing VMs by availability zones instead of nodes, use topologyKey: "topology.kubernetes.io/zone".
When using Affinity with topologyKey: "topology.kubernetes.io/zone", VMs will be placed in the same availability zone where a virtual machine with the specified labels is present.
When using AntiAffinity with topologyKey: "topology.kubernetes.io/zone", VMs will not be placed in the same availability zone as the virtual machine with the specified labels. This is useful for ensuring fault tolerance when distributing VMs across different availability zones.
To view availability zones on cluster nodes (if these zones are configured), run the following command:
d8 k get nodes -o custom-columns=NAME:.metadata.name,ZONE:.metadata.labels.topology\.kubernetes\.io/zone
Attaching block devices (disks and images)
Block devices can be divided into two types based on how they are connected: static and dynamic (hotplug).
Block devices and their features are shown in the table below:
| Block device type | Comment |
|---|---|
VirtualImage |
connected in read-only mode, or as a cdrom for iso images |
ClusterVirtualImage |
connected in read-only mode, or as a cdrom for iso images |
VirtualDisk |
connects in read/write mode |
Boot Block Devices
Boot block devices are defined in the virtual machine specification in the .spec.blockDeviceRefs block as a list. The order of the devices in this list determines the sequence in which they are loaded. Thus, if a disk or image is specified first, the loader will first try to boot from it. If it fails, the system will go to the next device in the list and try to boot from it. And so on until the first boot loader is detected.
Changing the composition and order of devices in the .spec.blockDeviceRefs block is possible only with a reboot of the virtual machine.
VirtualMachine configuration fragment with statically connected disk and project image:
spec:
blockDeviceRefs:
- kind: VirtualDisk
name: <virtual-disk-name>
- kind: VirtualImage
name: <virtual-image-name>
How to work with bootable block devices in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- On the “Configuration” tab, scroll down to the “Disks and Images” section.
- In the “Boot Disks” section you can:
Add: Attach a new disk or image to the VM.Extract: Detach the device from the VM (the image or disk remains in the project and can be attached again to this or another VM).Delete: Remove the image or disk resource from the cluster (after deletion it cannot be reused).Resize: Change the size of the disk.Reorder: Change the boot order of devices.
Additional Block Devices
Additional block devices can be connected to and disconnected from a running virtual machine without having to reboot it.
The VirtualMachineBlockDeviceAttachment (vmbda) resource is used to connect additional block devices.
As an example, create the following share that connects an empty blank-disk disk to a linux-vm virtual machine:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineBlockDeviceAttachment
metadata:
name: attach-blank-disk
spec:
blockDeviceRef:
kind: VirtualDisk
name: blank-disk
virtualMachineName: linux-vm
EOF
After creation, VirtualMachineBlockDeviceAttachment can be in the following states (phases):
Pending: Waiting for all dependent resources to be ready.InProgress: The process of device connection is in progress.Attached: The device is connected.
Diagnosing problems with a resource is done by analyzing the information in the .status.conditions block
Check the state of your resource:
d8 k get vmbda attach-blank-disk
Example output:
NAME PHASE VIRTUAL MACHINE NAME AGE
attach-blank-disk Attached linux-vm 3m7s
Connect to the virtual machine and make sure the disk is connected:
d8 v ssh cloud@linux-vm --local-ssh --command "lsblk"
Example output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 10G 0 disk <--- statically mounted linux-vm-root disk
|-sda1 8:1 0 9.9G 0 part /
|-sda14 8:14 0 4M 0 part
`-sda15 8:15 0 106M 0 part /boot/efi
sdb 8:16 0 1M 0 disk <--- cloudinit
sdc 8:32 0 95.9M 0 disk <--- dynamically mounted disk blank-disk
To detach the disk from the virtual machine, delete the previously created resource:
d8 k delete vmbda attach-blank-disk
Attaching images is done by analogy. To do this, specify VirtualImage or ClusterVirtualImage and the image name as kind:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineBlockDeviceAttachment
metadata:
name: attach-ubuntu-iso
spec:
blockDeviceRef:
kind: VirtualImage # or ClusterVirtualImage
name: ubuntu-iso
virtualMachineName: linux-vm
EOF
How to work with additional block devices in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- On the “Configuration” tab, scroll down to the “Disks and Images” section.
- In the “Additional Disks” section you can:
Add: Attach a new disk or image to the VM.Extract: Detach the device from the VM (the image or disk remains in the project and can be attached again to this or another VM).Delete: Remove the image or disk resource from the cluster (after deletion it cannot be reused).Resize: Change the size of the disk.
Disk naming in guest OS
Block device names (/dev/sda, /dev/sdb, /dev/sdc, etc.) are assigned by the Linux kernel in the order devices are discovered during boot. This order may change between reboots, so device names can change even if SCSI addresses remain the same.
Using /dev/sdX in configuration files (for example, /etc/fstab) or scripts may cause the wrong disk to be mounted or the VM to behave incorrectly after a reboot.
Example:
After the first VM boot:
$ lsscsi
[0:0:0:1] disk QEMU QEMU HARDDISK /dev/sda
[0:0:0:2] disk QEMU QEMU HARDDISK /dev/sdb
After VM reboot:
$ lsscsi
[0:0:0:1] disk QEMU QEMU HARDDISK /dev/sdb
[0:0:0:2] disk QEMU QEMU HARDDISK /dev/sda
SCSI addresses (0:0:0:1, 0:0:0:2) remain unchanged, but device names (/dev/sda, /dev/sdb) are swapped.
Use stable identifiers instead of /dev/sdX:
/dev/disk/by-uuid/— by partition UUID (preferred for/etc/fstab)/dev/disk/by-path/— by SCSI connection path/dev/disk/by-id/— by SCSI device ID
In configuration files and scripts, use partition UUIDs or symlinks from /dev/disk/by-* instead of /dev/sdX names.
Network interface naming in guest OS
In systems without predictable network interface naming support, network interface names (eth0, eth1, eth2, etc.) are assigned by the Linux kernel in the order devices are discovered during boot. When adding new network interfaces or changing the order of networks in .spec.networks, the interface order may change, which can cause IP addresses to be assigned to the wrong interfaces.
Using ethX in configuration files (for example, /etc/network/interfaces, netplan, systemd-networkd) or scripts may lead to unexpected network behavior or connection to the wrong network when adding new interfaces or changing the network order.
Modern distributions with systemd (Ubuntu 16.04+, Debian 9+, CentOS 7+, RHEL 7+) use predictable interface names (enpXsY, ensX, enoX) by default, which are based on the physical characteristics of the device (PCI coordinates) and remain stable between reboots and when adding new interfaces.
However, even when using predictable names, it is recommended to bind network configuration to interface MAC addresses for guaranteed stability, especially when changing the order of networks in .spec.networks or adding new interfaces.
Example for systems without predictable naming:
Initially, the VM has two interfaces:
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
After adding a new interface at the beginning of the .spec.networks list and rebooting the VM:
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 # New interface
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 # Old eth0
4: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 # Old eth1
MAC addresses remain unchanged, but interface names (eth0, eth1) shift, which can lead to IP addresses being assigned to the wrong interfaces.
Use stable identifiers instead of ethX:
enpXsY— predictable names based on physical location (systemd networkd naming scheme, enabled by default in modern systems)- MAC address binding — in
netplan,systemd-networkd, or/etc/network/interfacesconfiguration (preferred for guaranteed stability)
In configuration files and scripts, use stable interface names (enpXsY) or MAC address binding instead of ethX names.
Predictable interface order works only on guest OS with systemd (e.g. Ubuntu, Debian). On Alpine and other distros without systemd the order may not match.
Organizing interaction with virtual machines
Virtual machines can be accessed directly via their fixed IP addresses. However, this approach has limitations: direct use of IP addresses requires manual management, complicates scaling, and makes the infrastructure less flexible. An alternative is services—a mechanism that abstracts access to VMs by providing logical entry points instead of binding to physical addresses.
If connecting to a VM from a cluster node does not work, check NetworkPolicy in the project. Project network policies can restrict access to the VM, including connections from cluster nodes.
Services simplify interaction with both individual VMs and groups of similar VMs. For example, the ClusterIP service type creates a fixed internal address that can be used to access both a single VM and a group of VMs, regardless of their actual IP addresses. This allows other system components to interact with resources through a stable name or IP, automatically directing traffic to the right machines.
Services also serve as a load balancing tool: they distribute requests evenly among all connected machines, ensuring fault tolerance and ease of expansion without the need to reconfigure clients.
For scenarios where direct access to specific VMs within the cluster is important (for example, for diagnostics or cluster configuration), headless services can be used. Headless services do not assign a common IP, but instead link the DNS name to the real addresses of all connected machines. A request to such a name returns a list of IPs, allowing you to select the desired VM manually while maintaining the convenience of predictable DNS records.
For external access, services are supplemented with mechanisms such as NodePort, which opens a port on a cluster node, LoadBalancer, which automatically creates a cloud load balancer, or Ingress, which manages HTTP/HTTPS traffic routing.
All these approaches are united by their ability to hide the complexity of the infrastructure behind simple interfaces: clients work with a specific address, and the system itself decides how to route the request to the desired VM, even if its number or status changes.
The service name is formed as <service-name>.<namespace or project name>.svc.<clustername>, or more briefly: <service-name>.<namespace or project name>.svc. For example, if your service name is http and the namespace is default, the full DNS name will be http.default.svc.cluster.local.
The VM’s membership in the service is determined by a set of labels. To set labels on a VM in the context of infrastructure management, use the following command:
d8 k label vm <vm-name> label-name=label-value
Example:
d8 k label vm linux-vm app=nginx
Example output:
virtualmachine.virtualization.deckhouse.io/linux-vm labeled
How to add labels and annotations to VMs in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the desired VM from the list and click on its name.
- Go to the “Meta” tab.
- You can add labels in the “Labels” section.
- You can add annotations in the “Annotations” section.
- Click “Add” in the desired section.
- In the pop-up window, you can set the “Key” and “Value” of the key.
- To confirm the key parameters, click the “Enter” button.
- Click the “Save” button that appears.
Headless service
A headless service allows you to easily route requests within a cluster without the need for load balancing. Instead, it simply returns all IP addresses of virtual machines connected to this service.
Even if you use a headless service for only one virtual machine, it is still useful. By using a DNS name, you can access the machine without depending on its current IP address. This simplifies management and configuration because other applications within the cluster can use this DNS name to connect instead of using a specific IP address, which may change.
Example of creating a headless service:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: http
namespace: default
spec:
clusterIP: None
selector:
# Label by which the service determines which virtual machine to direct traffic to.
app: nginx
EOF
After creation, the VM or VM group can be accessed by name: http.default.svc
ClusterIP service
ClusterIP is a standard service type that provides an internal IP address for accessing the service within the cluster. This IP address is used to route traffic between different components of the system. ClusterIP allows virtual machines to interact with each other through a predictable and stable IP address, which simplifies internal communication within the cluster.
Example ClusterIP configuration:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: http
spec:
selector:
# Label by which the service determines which virtual machine to route traffic to.
app: nginx
EOF
How to perform the operation in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Network” → “Services” section.
- In the window that opens, configure the service settings.
- Click on the “Create” button.
Publish virtual machine services using a service with the NodePort type
NodePort is an extension of the ClusterIP service that provides access to the service through a specified port on all nodes in the cluster. This makes the service accessible from outside the cluster through a combination of the node’s IP address and port.
NodePort is suitable for scenarios where direct access to the service from outside the cluster is required without using a external load balancer.
Create the following service:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: linux-vm-nginx-nodeport
spec:
type: NodePort
selector:
# label by which the service determines which virtual machine to direct traffic to
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 31880
EOF
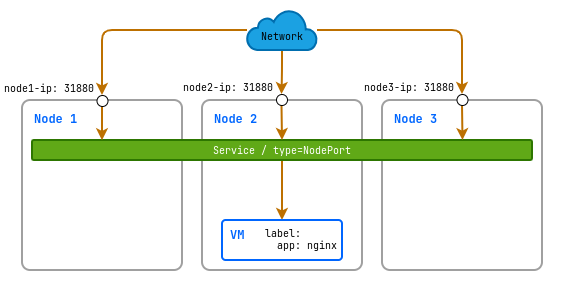
In this example, a service with the type NodePort will be created that opens external port 31880 on all nodes in your cluster. This port will forward incoming traffic to internal port 80 on the virtual machine where the Nginx application is running.
If you do not explicitly specify the nodePort value, an arbitrary port will be assigned to the service, which can be viewed in the service status immediately after its creation.
Publishing virtual machine services using a service with the LoadBalancer service type
LoadBalancer is a type of service that automatically creates an external load balancer with a static IP address. This balancer distributes incoming traffic among virtual machines, ensuring the service’s availability from the Internet.
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: linux-vm-nginx-lb
spec:
type: LoadBalancer
selector:
# label by which the service determines which virtual machine to direct traffic to
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
EOF
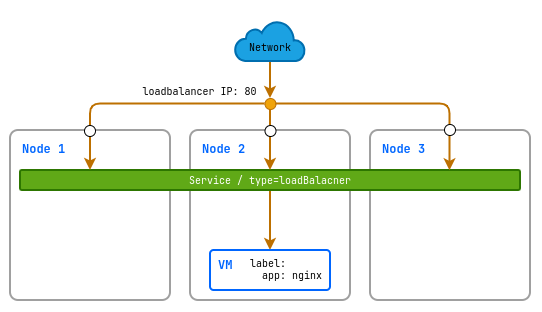
Publish virtual machine services using Ingress
Ingress allows you to manage incoming HTTP/HTTPS requests and route them to different servers within your cluster. This is the most appropriate method if you want to use domain names and SSL termination to access your virtual machines.
To publish a virtual machine service through Ingress, you must create the following resources:
An internal service to bind to Ingress. Example:
d8 k apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: linux-vm-nginx
spec:
selector:
# label by which the service determines which virtual machine to direct traffic to
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
EOF
And an Ingress resource for publishing. Example:
d8 k apply -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: linux-vm
spec:
rules:
- host: linux-vm.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: linux-vm-nginx
port:
number: 80
EOF
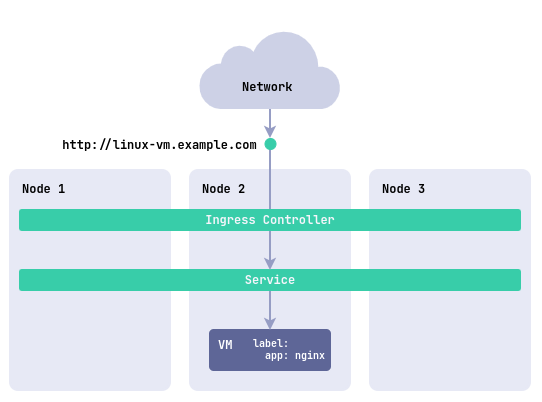
How to publish a VM service using Ingress in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Network” → “Ingresses” section.
- Click the “Create Ingress” button.
- In the window that opens, configure the service settings.
- Click the “Create” button.
Live virtual machine migration
Live virtual machine (VM) migration is the process of moving a running VM from one physical host to another without shutting it down. This feature plays a key role in managing virtualized infrastructure, ensuring application continuity during maintenance, load balancing, or upgrades.
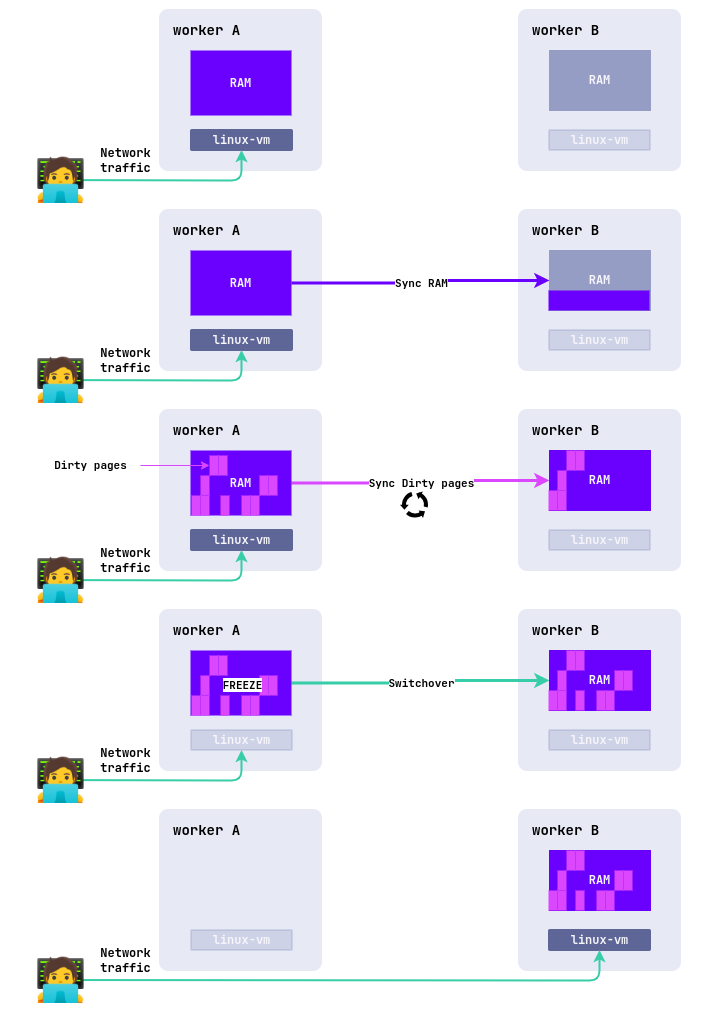
How live migration works
The live migration process involves several steps:
-
Creation of a new VM instance
A new VM is created on the target node in a suspended state. Its configuration (CPU, disks, network) is copied from the source node.
-
Primary memory transfer
The entire RAM of the VM is copied to the target node over the network. This is called primary transfer.
-
Change tracking (Dirty Pages)
While memory is being transferred, the VM continues to run on the source node and may change some memory pages. These pages are called dirty pages, and the hypervisor marks them.
-
-
Iterative synchronization.
After the initial transfer, only the modified pages are sent again. This process is repeated over several cycles:
- The higher the load on the VM, the more “dirty” pages appear, and the longer the migration takes.
- With good network bandwidth, the amount of unsynchronized data gradually decreases.
-
Final synchronization and switching
When the number of dirty pages becomes minimal, the VM on the source node is suspended (typically for 100 milliseconds):
- The remaining memory changes are transferred to the target node.
- The state of the CPU, devices, and open connections are synchronized.
- The VM is started on the new node, and the source copy is deleted.
Until the VM switches to the new node (Phase 5), the VM on the source node continues to operate normally and provide services to users.
Requirements and limitations
For successful live migration, certain requirements must be met. Failure to meet these requirements can lead to limitations and issues during migration.
-
Disk availability: All disks attached to the VM must be accessible on the target node, otherwise migration will be impossible. For network storage (NFS, Ceph, etc.), this requirement is usually met automatically, as disks are accessible on all cluster nodes. For local storage, the situation is different: the storage system must be available on the target node to create a new local volume. If local storage exists only on the source node, migration cannot be performed.
-
Network bandwidth: Network speed is critical for live migration. With low bandwidth, the number of memory synchronization iterations increases, VM downtime during the final stage of migration increases, and in the worst case, migration may not complete due to a timeout. To manage the migration process, configure the live migration policy
.spec.liveMigrationPolicyin the virtual machine settings. For network problems, use the AutoConverge mechanism (see the Migration with insufficient network bandwidth section). -
Kernel versions on nodes: For stable live migration operation, all cluster nodes must use the same Linux kernel version. Differences in kernel versions can lead to incompatible interfaces, system calls, and resource handling features, which can disrupt the virtual machine migration process.
-
CPU compatibility: CPU compatibility depends on the CPU type specified in the virtual machine class. When using the
Hosttype, migration is only possible between nodes with similar CPU types: migration between nodes with Intel and AMD processors does not work, and it also does not work between different CPU generations due to differences in instruction sets. When using theHostPassthroughtype, the VM can only migrate to a node with exactly the same processor as on the source node. To ensure migration compatibility between nodes with different processors, use theDiscovery,Model, orFeaturestypes in the virtual machine class. -
Migration execution time: A completion timeout is set for live migration, which is calculated using the formula:
Completion timeout = 800 seconds × (Memory size in GiB + Disk size in GiB (if Block Migration is used)). If migration does not complete within this time, the operation is considered failed and is canceled automatically. For example, for a virtual machine with 4 GiB of memory and 20 GiB of disk, the timeout will be800 seconds × (4 GiB + 20 GiB) = 19200 seconds (320 minutes or ~5.3 hours). With low network speed or high load on the VM, migration may not complete within the allotted time.
How to perform a live VM migration
Let’s look at an example. Before starting the migration, view the current status of the virtual machine:
d8 k get vm
Example output:
NAME PHASE NODE IPADDRESS AGE
linux-vm Running virtlab-pt-1 10.66.10.14 79m
We can see that it is currently running on the virtlab-pt-1 node.
To migrate a virtual machine from one node to another while taking into account VM placement requirements, use the following command:
d8 v evict -n <namespace> <vm-name> [--force]
Running this command creates a VirtualMachineOperations resource.
When used during virtual machine migration, the --force flag activates a special mechanism called AutoConverge (for more details, see the Migration with insufficient network bandwidth section). This mechanism automatically reduces the CPU load of the virtual machine (slows down its CPU) when it is necessary to speed up the completion of migration and help it complete successfully, even when the virtual machine memory transfer is too slow. Use this flag if a standard migration cannot complete due to high virtual machine activity.
You can also start the migration by creating a VirtualMachineOperations (vmop) resource with the Evict type manually:
d8 k create -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineOperation
metadata:
generateName: evict-linux-vm-
spec:
# virtual machine name
virtualMachineName: linux-vm
# operation to evict
type: Evict
# Allow CPU slowdown by AutoConverge mechanism to guarantee that migration will complete.
force: true
EOF
To track the migration of a virtual machine immediately after the vmop resource is created, run the command:
d8 k get vm -w
Example output:
NAME PHASE NODE IPADDRESS AGE
linux-vm Running virtlab-pt-1 10.66.10.14 79m
linux-vm Migrating virtlab-pt-1 10.66.10.14 79m
linux-vm Migrating virtlab-pt-1 10.66.10.14 79m
linux-vm Running virtlab-pt-2 10.66.10.14 79m
You can interrupt any live migration while it is in the Pending or InProgress phase by deleting the corresponding VirtualMachineOperations resource.
How to perform a live VM migration in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the desired virtual machine from the list and click the ellipsis button.
- Select “Migrate” from the pop-up menu.
- Confirm or cancel the migration in the pop-up window.
Configuring migration policy
The migration policy determines when to use the AutoConverge mechanism (CPU slowdown) to guarantee migration completion.
The AutoConverge mechanism helps complete migration even with low network bandwidth, guaranteeing that the migration will complete successfully. However, it slows down the virtual machine’s CPU, which can affect the performance of applications running on the virtual machine.
The AutoConverge mechanism works in two stages:
-
Virtual machine CPU slowdown
The hypervisor gradually reduces the CPU frequency of the source virtual machine. This reduces the rate at which new “dirty” pages appear. The higher the load on the virtual machine, the greater the slowdown.
-
Automatic migration completion
Once the data transfer rate exceeds the memory change rate, final synchronization is started, and the virtual machine switches to the new node.
To configure the migration policy, use the .spec.liveMigrationPolicy parameter in the virtual machine configuration. The following options are available:
AlwaysSafe: Migration is always performed without slowing down the CPU (AutoConverge is not used). Suitable for cases where maximum virtual machine performance is important, but it requires high network bandwidth.PreferSafe(used as the default policy): Migration is performed without slowing down the CPU (AutoConverge is not used). However, you can start migration with CPU slowdown using the VirtualMachineOperation resource with parameterstype=Evictandforce=true.AlwaysForced: Migration always uses AutoConverge, meaning the CPU is slowed down when necessary. This guarantees migration completion even with poor network, but may reduce virtual machine performance.PreferForced: Migration uses AutoConverge, meaning the CPU is slowed down when necessary. However, you can start migration without slowing down the CPU using the VirtualMachineOperation resource with parameterstype=Evictandforce=false.
Migration with insufficient network bandwidth
During live migration of a virtual machine, a situation may arise when network bandwidth is insufficient to transfer data faster than it changes in the virtual machine’s memory. In this case, the number of “dirty” pages continues to grow, and the migration may not complete within the timeout.
To solve this problem, the AutoConverge mechanism is used, which is configured through the migration policy.
To determine whether network bandwidth is insufficient for live migration of a virtual machine, check the graphs in the “Namespace / Virtual Machine” → “VM Status details” → “Live migration memory metrics” section:
- Processed memory rate is less than Dirty memory rate.
- Remaining memory rate does not decrease for a long time.
This means that the network has become a bottleneck for migration.
Example of a situation where migration cannot be completed due to insufficient network bandwidth: memory is continuously changed inside the virtual machine using stress-ng.
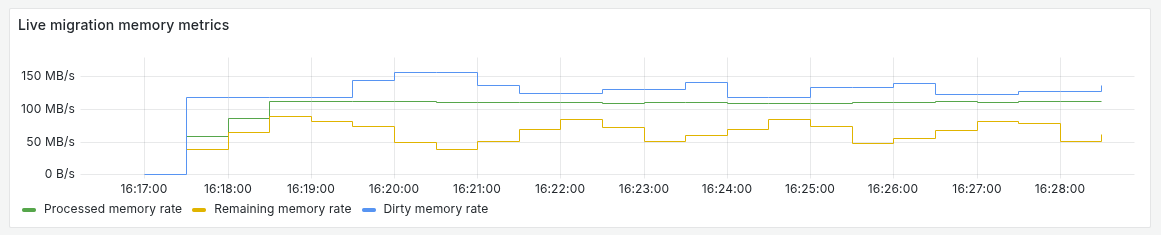
Example of performing migration of the same virtual machine using the --force flag of the d8 v evict command (which enables the AutoConverge mechanism): here you can clearly see that the CPU frequency decreases step by step to reduce the memory change rate.
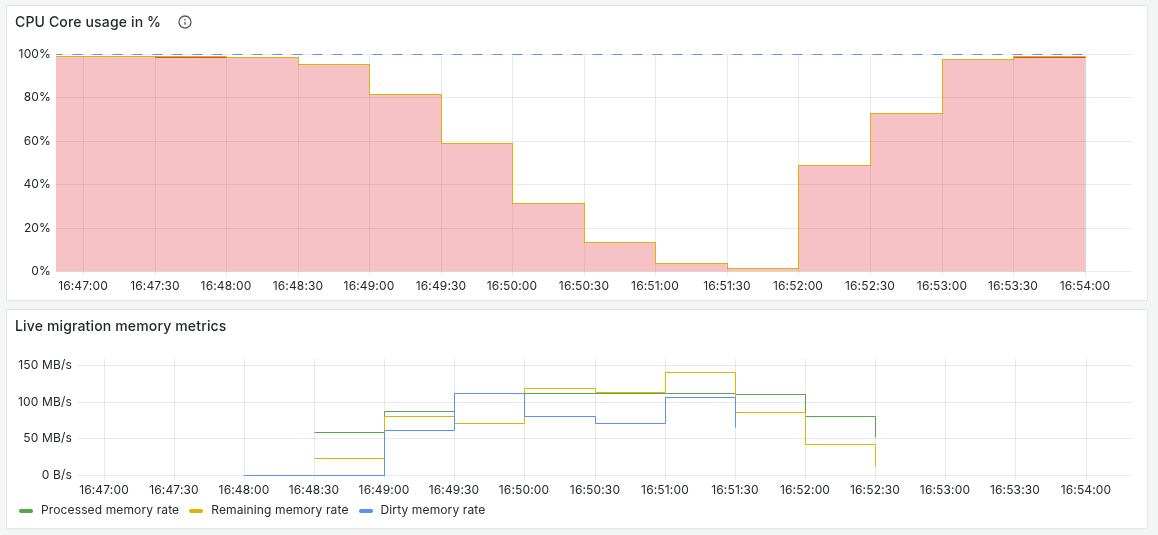
If the network limits the migration speed, you can:
- Wait for the operation to complete with an error due to timeout.
-
Cancel the current migration operation by deleting the vmop object:
d8 k delete vmop <operation-name>Then restart the migration using the
--forceflag to enable the AutoConverge mechanism. Using the--forceflag must comply with the current virtual machine migration policy.
System-initiated migrations
Migration can be performed automatically by the following system events:
- Updating the “firmware” of a virtual machine.
- Redistribution of load in the cluster.
- Transferring a node into maintenance mode (Node drain).
- When you change VM placement settings (not available in Community edition).
The trigger for live migration is the appearance of the VirtualMachineOperations resource with the Evict type.
The table shows the VirtualMachineOperations resource name prefixes with the Evict type that are created for live migrations caused by system events:
| Type of system event | Resource name prefix |
|---|---|
| Firmware update | firmware-update-* |
| Load redistribution in the cluster | evacuation-* |
| Node drain | evacuation-* |
| VM placement settings change | nodeplacement-update-* |
| Disk storage migration | volume-migration-* |
This resource can be in the following states:
Pending: The operation is pending.InProgress: Live migration is in progress.Completed: Live migration of the virtual machine has completed successfully.Failed: Live migration of the virtual machine has failed.
You can view active operations using the command:
d8 k get vmop
Example output:
NAME PHASE TYPE VIRTUALMACHINE AGE
firmware-update-fnbk2 Completed Evict linux-vm 148m
To cancel the migration, delete the corresponding resource.
How to view active operations in the web interface:
- Go to the “Projects” tab and select the desired project.
- Go to the “Virtualization” → “Virtual Machines” section.
- Select the required VM from the list and click on its name.
- Go to the “Events” tab.
Live migration of virtual machine when changing placement parameters (not available in CE edition)
Let’s consider the migration mechanism on the example of a cluster with two node groups (NodeGroups): green and blue. Suppose a virtual machine (VM) is initially running on a node in the green group and its configuration contains no placement restrictions.
Step 1: Add the placement parameter Let’s specify in the VM specification the requirement for placement in the green group :
spec:
nodeSelector:
node.deckhouse.io/group: green
After saving the changes, the VM will continue to run on the current node, since the nodeSelector condition is already met.
Step 2: Change the placement parameter Let’s change the placement requirement to group blue :
spec:
nodeSelector:
node.deckhouse.io/group: blue
Now the current node (groups green) does not match the new conditions. The system will automatically create a VirtualMachineOperations object of type Evict, which will initiate a live migration of the VM to an available node in group blue .
Collecting debug information
The collect-debug-info command requires d8 version v0.27.0 or higher.
Use collect-debug-info to gather diagnostic data about a virtual machine and all related resources into a single compressed archive.
The command collects the following information:
- Virtual machine configuration
- Virtual machine operations
- Migration information
- Block devices
- Related PVCs and PVs
- Pods associated with the VM, including their logs (last 10000 lines)
- Events for all related resources
- VM domain XML configuration
The command output is written to a compressed archive (tar.gz) that is output to stdout. To save the archive, you must redirect the output to a file.
Usage example:
# Collect debug information for virtual machine 'linux-vm'
d8 v collect-debug-info linux-vm > debug-info.tar.gz
# Collect debug information for VM with namespace specified
d8 v collect-debug-info linux-vm -n mynamespace > debug-info.tar.gz
# Collect debug information for VM with full name specified (name.namespace)
d8 v collect-debug-info linux-vm.mynamespace > debug-info.tar.gz
The command cannot output data directly to the terminal. You must redirect the output to a file, otherwise the command will fail with an error.
After executing the command, you will receive a debug-info.tar.gz archive that contains all collected data in YAML format (for resources) and text files (for logs). This archive can be sent to technical support for problem analysis.
Network configuration
IP addresses of virtual machines
The .spec.settings.virtualMachineCIDRs block in the virtualization module configuration specifies a list of subnets to assign IP addresses to virtual machines (a shared pool of IP addresses). All addresses in these subnets are available for use except the first (network address) and the last (broadcast address). For example:
- In subnet
10.20.30.0/26, the addresses10.20.30.0and10.20.30.63are reserved. - In subnet
10.20.30.64/26, the addresses10.20.30.64and10.20.30.127are reserved.
VirtualMachineIPAddressLease (vmipl) resource: A cluster resource that manages IP address leases from the shared pool specified in virtualMachineCIDRs.
To see a list of IP address leases (vmipl), use the command:
d8 k get vmipl
Example output:
NAME VIRTUALMACHINEIPADDRESS STATUS AGE
ip-10-66-10-14 {"name":"linux-vm-7prpx","namespace":"default"} Bound 12h
VirtualMachineIPAddress (vmip) resource: A project/namespace resource that is responsible for reserving leased IP addresses and binding them to virtual machines. IP addresses can be allocated automatically or by explicit request.
After creation, the VirtualMachineIPAddress resource can have the following Phase values:
Pending: Resource is being created.Bound: VirtualMachineIPAddress is bound to the VirtualMachineIPAddressLease resource.Attached: VirtualMachineIPAddress is attached to the VirtualMachine resource.
By default, an ip address is automatically assigned to a virtual machine from the subnets defined in the module and is assigned to it until it is deleted. You can check the assigned ip address using the command:
d8 k get vmip
Example output:
NAME ADDRESS STATUS VM AGE
linux-vm-7prpx 10.66.10.14 Attached linux-vm 12h
The algorithm for automatically assigning an ip address to a virtual machine is as follows:
- The user creates a virtual machine named
<vmname>. - The module controller automatically creates a
vmipresource named<vmname>-<hash>to request an IP address and associate it with the virtual machine. - To do this,
vmipcreates avmipllease resource that selects a random IP address from a shared pool. - Once the
vmipresource is created, the virtual machine receives the assigned IP address.
The virtual machine’s IP address is assigned automatically from the subnets defined in the module and remains assigned to the machine until it is deleted. After the virtual machine is deleted, the vmip resource is also deleted, but the IP address remains temporarily assigned to the project/namespace and can be re-requested explicitly.
The full description of vmip and vmipl machine resource configuration parameters can be found at the links:
How to request a required ip address?
Task: request a specific ip address from the virtualMachineCIDRs subnets.
Create a vmip resource:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineIPAddress
metadata:
name: linux-vm-custom-ip
spec:
staticIP: 10.66.20.77
type: Static
EOF
Create a new or modify an existing virtual machine and specify the required vmip resource explicitly in the specification:
spec:
virtualMachineIPAddressName: linux-vm-custom-ip
How to save the ip address assigned to the virtual machine?
Objective: to save the ip address issued to a virtual machine for reuse after the virtual machine is deleted.
To ensure that the automatically assigned ip address of a virtual machine is not deleted along with the virtual machine itself, perform the following steps.
Obtain the vmip resource name for the specified virtual machine:
d8 k get vm linux-vm -o jsonpath="{.status.virtualMachineIPAddressName}"
# linux-vm-7prpx
Remove the .metadata.ownerReferences blocks from the resource found:
d8 k patch vmip linux-vm-7prpx --type=merge --patch '{"metadata":{"ownerReferences":null}}'
# Alternatively, apply the changes by editing the resource.
d8 k edit vmip linux-vm-7prpx
After the virtual machine is deleted, the vmip resource is preserved and can be reused again in the newly created virtual machine:
spec:
virtualMachineIPAddressName: linux-vm-7prpx
Even if the vmip resource is deleted, IP address remains rented for the current project/namespace for another 10 minutes. Therefore, it is possible to reoccupy it on request:
d8 k apply -f - <<EOF
apiVersion: virtualization.deckhouse.io/v1alpha2
kind: VirtualMachineIPAddress
metadata:
name: linux-vm-custom-ip
spec:
staticIP: 10.66.20.77
type: Static
EOF
Additional network interfaces
To work with additional networks, the sdn module must be enabled.
Virtual machines can be connected to additional networks: project networks (Network) or cluster networks (ClusterNetwork).
To do this, specify the desired networks in the configuration section .spec.networks. If this block is not specified (which is the default behavior), the VM will use only the main cluster network.
Specifying the main cluster network (type: Main) in .spec.networks is optional. If you do not need connectivity to the main cluster network, you can use only additional networks (Network or ClusterNetwork).
If you specify the main network, it must be the first entry in the .spec.networks list.
Important considerations when working with additional network interfaces:
- The order of listing networks in
.spec.networksdetermines the order in which interfaces are connected inside the virtual machine. - Adding or removing additional networks takes effect only after the VM is rebooted.
- To preserve the order of network interfaces inside the guest operating system, it is recommended to add new networks to the end of the
.spec.networkslist (do not change the order of existing ones). - Network security policies (NetworkPolicy) do not apply to additional network interfaces.
- Network parameters (IP addresses, gateways, DNS, etc.) for additional networks are configured manually from within the guest OS (for example, using Cloud-Init).
When configuring network interfaces in the guest OS, use stable identifiers (predictable names enpXsY or MAC address binding) instead of ethX names. For more details, see the Network interface naming in guest OS section.
On a Linux guest system with multiple interfaces in the same subnet, the ARP Flux issue may occur, where the kernel responds to ARP requests via any arbitrary interface rather than the one the request was received on, leading to unstable connections and packet loss due to an incorrect MAC address in the router’s ARP cache.
To resolve this, set the following parameters to force the system to respond to requests strictly via the interface holding the target IP and to use the correct source address:
sysctl -w net.ipv4.conf.all.arp_ignore=1
sysctl -w net.ipv4.conf.all.arp_announce=2
Cloud-init example:
write_files:
- path: /etc/sysctl.d/90-arp-strict.conf
content: |
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.all.arp_announce=2
For more details, see the IP sysctl documentation.
Example of connecting a VM to the main cluster network and the project network user-net:
spec:
networks:
- type: Main # If specified, must be first
- type: Network # Network type (Network \ ClusterNetwork)
name: user-net # Network name
Example of connecting to multiple networks, including the cluster network corp-net:
spec:
networks:
- type: Main # If specified, must be first
- type: Network
name: user-net
- type: ClusterNetwork
name: corp-net # Network name
Example of connecting a VM only to additional networks (without the main cluster network):
spec:
networks:
- type: Network
name: isolated-net
- type: ClusterNetwork
name: corp-net
You can view information about connected networks and their MAC addresses in the VM status:
status:
networks:
- type: Main
- type: Network
name: user-net
macAddress: aa:bb:cc:dd:ee:01
- type: ClusterNetwork
name: corp-net
macAddress: aa:bb:cc:dd:ee:02
For each additional network interface, a unique MAC address is automatically generated and reserved to avoid collisions. The following resources are used for this: VirtualMachineMACAddress (vmmac) and VirtualMachineMACAddressLease (vmmacl).
The MAC address is generated randomly from the allowed ranges:
- Ranges:
x2-xx-xx-xx-xx-xx,x6-xx-xx-xx-xx-xx,xA-xx-xx-xx-xx-xx,xE-xx-xx-xx-xx-xx. - The first three octets (OUI) are formed based on the cluster UUID, the last three (NIC) are chosen randomly from 16 million possible combinations.
VirtualMachineMACAddressLease (vmmacl) is a cluster resource that manages the lease of MAC addresses from the shared MAC address pool.
To see the list of MAC address leases (vmmacl), use the command:
d8 k get vmmacl
Example output:
NAME VIRTUALMACHINEMACADDRESS STATUS AGE
mac-5e-e6-19-22-0f-d8 {"name":"vm-01-fz9cr","namespace":"pr-sdn"} Bound 45s
mac-5e-e6-19-29-89-cf {"name":"vm-01-99qj6","namespace":"pr-sdn"} Bound 45s
mac-5e-e6-19-54-f9-be {"name":"vm-01-5jqxg","namespace":"pr-sdn"} Bound 45s
VirtualMachineMACAddress (vmmac) is a project-level resource that is responsible for reserving leased MAC addresses and binding them to virtual machines.
MAC addresses are automatically assigned to each additional VM interface from the shared address pool and remain assigned until the VM is deleted.
You can check the assigned MAC addresses using the command:
d8 k get vmmac
Example output:
NAME ADDRESS STATUS VM AGE
vm-01-5jqxg 5e:e6:19:54:f9:be Attached vm-01 5m42s
vm-01-99qj6 5e:e6:19:29:89:cf Attached vm-01 5m42s
vm-01-fz9cr 5e:e6:19:22:0f:d8 Attached vm-01 5m42s
When a network is removed from the VM configuration:
- The MAC address of the interface is released.
- The associated
VirtualMachineMACAddressandVirtualMachineMACAddressLeaseresources are automatically deleted.